
これはなに?
GaOTTTというものを作っています。
正式名称は、
Gravity as Optimizer, Test-Time Training。
ニュアンスも含めた日本語にすると、 「推論時学習っ! —重力は最適化器!?—」 という感じです。
どういうことなのかよくわからないですよね。私もそう思います。
これは一言で言うと、 「LLMのための長期記憶システム」 です。
ただし、一般的に長期記憶として使われる普通のRAGやハーネスとは少し違います。
普通のRAGは、ざっくり言えば、
質問する
関係ありそうな文書を探す
それをLLMに渡す
という仕組みです。
一方で、ここで言うハーネスは、LLMの前後にプロンプト、ツール、ルール、状態管理、権限管理、実行環境などを組み合わせて、モデルの振る舞いを外側から制御する仕組みです。
ざっくり言えば、
モデルそのものを書き換えるのではなく、
コンテキスト、ツール、ルール、環境によって次の挙動を誘導・制約する
仕組みです。
Claude CodeやCodex CLIのようなコーディングエージェントでやっていることは、その代表例だと思います。
たとえば、プロジェクトのルールを読み込ませる。
使えるツールを制限する。
どのファイルを編集してよいかを決める。
テストを実行させる。
必要なら人間に確認を求める。
そういった外側の足場によって、LLMを単なるチャットモデルではなく、作業するエージェントとして動かす。
最近は、こうした外側の設計を、プロンプトエンジニアリングより広い意味で「コンテキストエンジニアリング」や「ハーネスエンジニアリング」と呼ぶこともあります。
もちろん、それだけでも便利です。
便利なのですが、私はそこに少し物足りなさを感じていました。
なぜなら、人間の記憶は、たぶんそんなに平らではないからです。
何度も思い出したことは、少し近くなる。
一緒に思い出されたものは、少し結びつく。
強い感情を伴った記憶は、周囲の記憶を引っ張る。
忘れていたものでも、ある文脈に入ると、突然ふわっと浮かび上がってくる。
そういう、記憶の「場」みたいなものがあります。
GaOTTTは、それをLLMの外側に作ろうとした実験です。
どこから始まったのか
GaOTTTは、最初から「Test-Time Training的なシステムを作ろう」と思って始めたものではありません。
むしろ順番としては、かなり逆でした。
最初にあったのは、
重力って、学習器っぽくない?
という感覚でした。

物体が互いに引き合う。
重いものほど、周囲の軌道を曲げる。
何度も近くを通るものは、同じ場の中で影響を受け続ける。
場そのものが、そこを通ったものの運動を決める。
この構造は、なんとなく「記憶」や「学習」に似ています。
もちろん、これは物理としての重力をそのまま機械学習に持ち込む、という話ではありません。
最初にあったのは、もっと素朴な比喩です。
例えばものすごく嬉しかったこと、あるいはトラウマ的な記憶は、ずっと頭の中に残り続けて、将来の行動を拘束するハーネスとして機能します。
私はトラウマの塊みたいな記憶があるので、何を考えるにしても常にそれが頭の中をよぎります。
そこから連想したことが、記憶にも、引力があるのではないか。
何度も思い出される記憶は、重くなるのではないか。
重くなった記憶は、次に思い出されるものを少し曲げるのではないか。
そして、その曲がり方そのものが、ある種の学習なのではないか。
そんなところから始まりました。
最初から論文の概念を作りたかったり実装しようとしたというより、
まず、記憶空間を「重力場」として見る直感を形にしたかったのです。
そのあとで、
あれ、これは最適化っぽく読めるのでは?
と思うようになりました。
RAGではなく、記憶空間を育てたい
最初に言っておくと、GaOTTTはLLM本体の重みを更新しません。
なので、モデルそのものをファインチューニングしているわけではありません。
LLMの中身を書き換えているわけでもありません。
やっているのは、外部記憶側の幾何を少しずつ変えることです。
文書をノードとして置きます。
それぞれのノードには、質量があります。
温度があります。
位置があります。
そして、検索や想起のたびに、ノード同士の距離が少しだけ変わります。
よく一緒に思い出される記憶は、近づく。
何度も参照される記憶は、重くなる。
重くなった記憶は、次の検索を曲げる。
つまり、記憶空間が使われるたびに、少しずつ地形を変えていきます。
検索結果を返して終わりではなく、
検索したこと自体が、次の検索の条件を変えてしまう。
このあたりが、私がGaOTTTをただのRAGではなく、
外部記憶によるTest-Time Training的なものとして見ている理由です。
Heavy Ballとしての重力メタファー

「重力っぽい学習」という感覚は、重力がなぜ光を曲げるのかを説明する「ゴムシートの宇宙」から連想しています。
ゴムシートを張って、重い球を乗せるとそこがたわんで、光が到達するまでの距離が伸びる、という説明です。
これをあとから最適化の言葉で見ると、Heavy Ball法というものがあると知りました。
Heavy Ball法は、ざっくり言えば、勾配降下に「慣性」や「運動量」を持たせる方法です。
普通の勾配降下では、その時点の勾配を見て、パラメータを少し動かします。
一方でHeavy Ballやmomentumを持つ最適化では、過去の移動方向も少し覚えています。
つまり、
今の勾配
+
前まで進んでいた方向
を組み合わせて、次の更新方向を決める。
これはかなり物理っぽい。
パラメータ空間の中を、重い球が転がっているように見る。
勾配は力、過去の更新方向は速度です。
摩擦や減衰がありつつも、球は一度進み始めた方向へ進み続けようとする。
GaOTTTの実装も、実際にこの感覚に対応しています。記憶ノードには位置・速度・加速度があり、想起のたびに位置をVerlet積分(位置 → 速度 → 加速度 → 次の位置、の2ステップ)で更新します。
Verlet積分というのは、惑星の軌道計算や分子の運動計算など、物理シミュレーションで広く使われている数値計算の手法です。時間を細かく刻みながら、位置と速度をその都度ちょっとずつ更新していく、ボードゲームを1コマずつ進めるような計算方法だと思ってもらえれば近いです。「現在の位置と、その瞬間に働いている力(加速度)から、次の瞬間の位置を決める」を繰り返すことで、惑星の軌道のような曲がった運動を再現します。
物理シミュレーションとして書いたコードが、そのまま「過去の更新方向を持ち越す最適化」として読める。ここから先は、単なる比喩というより、かなり項ごとの構造的対応に近くなっていきます。
GaOTTTの重力場も、最初はこの感覚にかなり近いところから生まれています。
記憶ノードがあり、質量があり、引力があり、変位がある。
一度想起された記憶は、その場に痕跡を残す。
次の想起は、完全に独立した検索ではなく、前の想起によって少し曲げられる。
これは、単なる検索ではありません。
検索結果を返すだけなら、そこで終わりです。
でも、検索されたことによって、次の検索空間が少し変わる。
その意味で、GaOTTTの重力は、単なる視覚的メタファーではなく、
「過去の更新が次の更新に影響する」という、momentum的な学習器の比喩でもあります。
もちろん、これは「GaOTTTは数学的にHeavy Ball法そのものです」と言いたいわけではありません。
むしろ大事なのは、重力という直感が、あとから最適化の言葉で読めるようになったことです。
物理っぽい。
記憶っぽい。
最適化っぽい。
その三つが、あとから同じ方向を向いているように見えました。
グリア細胞っぽくない?という気づき
重力の挙動を図示したらかっこいいよね、という安直な理由から、GaOTTTには3次元マッピングした宇宙を描画するVisualizeという機能を付けました。
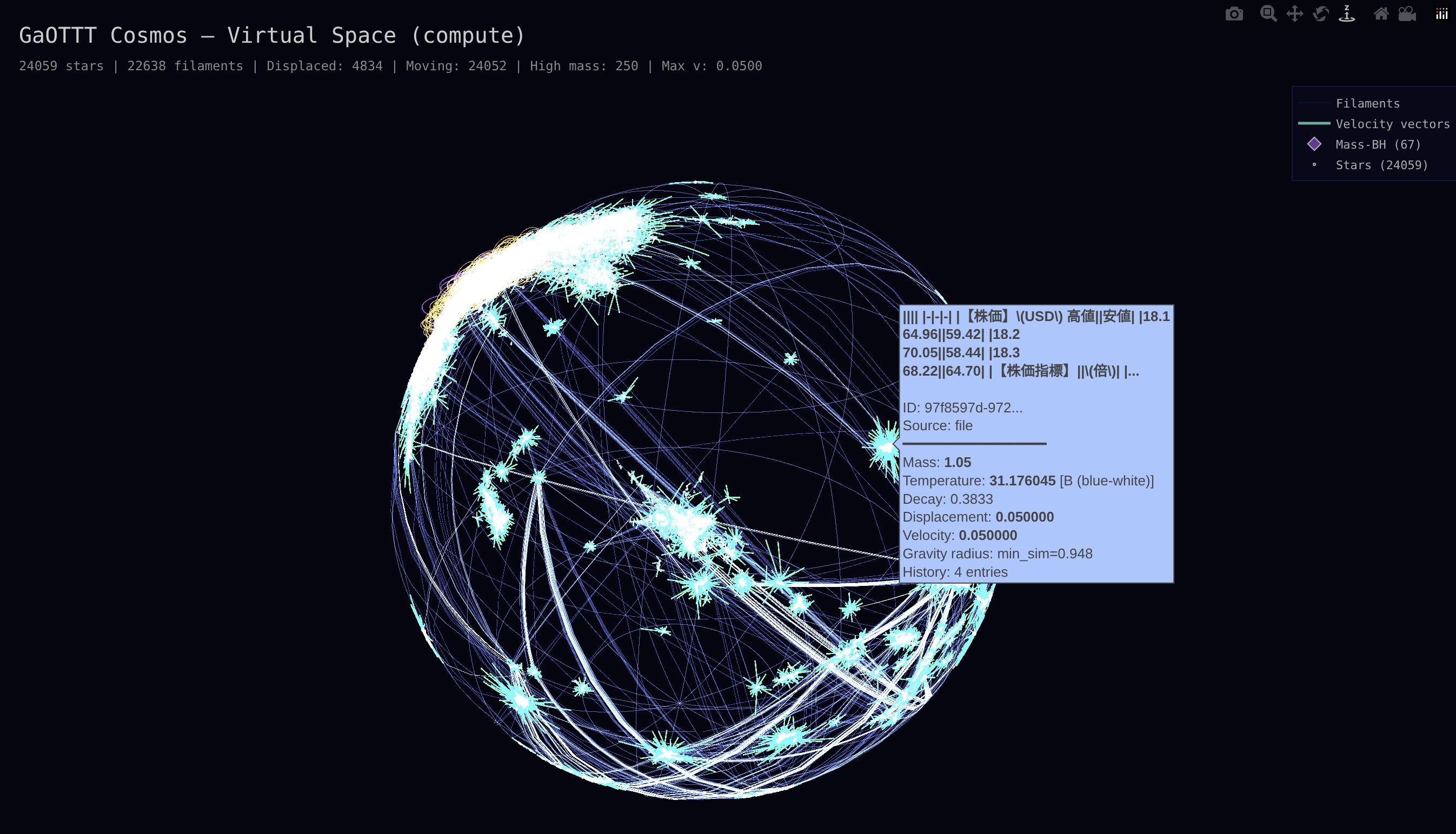
実際にこの出力を初めて見たとき、
これって、脳のグリア細胞っぽくない?
という感覚がありました。
脳というと、どうしてもニューロンが主役のように語られます。
ニューロンが発火する。
シナプスがつながる。
信号が流れる。
重みが変わる。
機械学習のニューラルネットワークも、だいたいこのニューロン中心のイメージで語られます。
でも実際の脳には、ニューロンだけではなく、ニューロンを支えたり、環境を整えたり、シナプス活動にも関わったりするグリア細胞があります。
その中でも星状膠細胞、アストロサイトは、名前の通り星のような形をしていて、細かい突起を広げながら、シナプスの周囲に入り込んでいきます。
ここが、GaOTTTのイメージとかなり重なりました。
ニューロンだけを見ると、情報は点から点へ流れているように見えます。
でも、星状膠細胞まで含めて見ると、シナプスの周囲には、もう少し広い「場」があります。
シナプス前ニューロン。
シナプス後ニューロン。
そして、その周囲にいるグリア細胞。
この三者をまとめて見る考え方は、tripartite synapse、三者間シナプスとも呼ばれます。
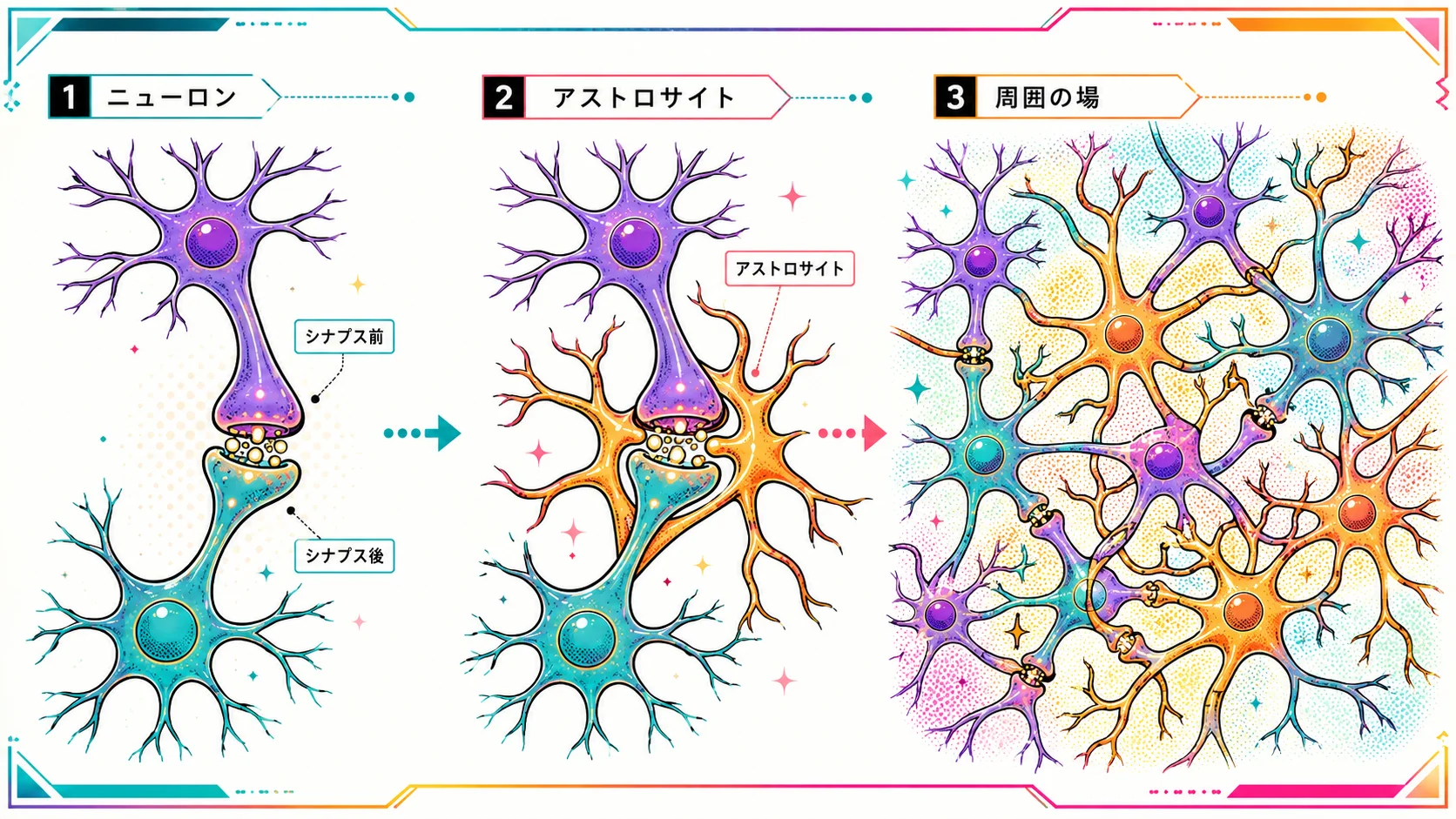
つまり、シナプスは単にニューロン同士の接点ではなく、
周囲のグリア細胞も含めた、局所的な情報処理の場として見られる。
この感じが、GaOTTTの記憶空間に近いと思いました。
そして、ニューロンそのものではなく、そこに「栄養」や「環境」を与えるものを作れば、実質的に出力の方向を変えることになるのではないか、とも思いました。
強化学習そのものではありません。
でも、「何が次に呼ばれやすくなるか」を環境側で調整する、かなりRL的な匂いのする構造ではあります。
ニューロンではなく、場を作るもの
GaOTTTでやっていることは、LLM本体のニューロンを直接いじることではありません。
LLMの重みは変えません。
モデル内部の層も変えません。
注意機構(attention)の中身を直接書き換えるわけでもありません。
それよりも、LLMの外側にある記憶の場を作ります。
エージェントが何かを考えるとき、
その外側の場から、関係する記憶が浮かび上がってくる。
何度も想起された記憶は、強くなる。
一緒に想起された記憶は、近くなる。
ある価値観やペルソナに関係する記憶は、次の応答に影響しやすくなる。
これは、ニューロンの発火そのものではありません。
むしろ、ニューロンの周囲で、情報の流れ方やシナプスの効き方を調整するグリア的な層に近い。
もちろん、GaOTTTが実際の脳を再現しているわけではありません。
グリア細胞の生物学的モデルを正確に実装しているわけでもありません。
でも、
主役の計算器そのものではなく、
その周囲にある場が、情報の流れ方を変える
という構造は、かなり似ています。
LLM本体がニューロン的な計算器だとしたら、
GaOTTTはその外側に広がる、グリア的な記憶場なのかもしれません。
ここで私が面白いと思っているのは、グリア細胞が単なる「補助役」ではないところです。
昔のイメージでは、グリア細胞はニューロンを支えるための支持細胞のように見られがちでした。
でも、星状膠細胞はシナプス活動に応答し、カルシウム信号を持ち、神経伝達や可塑性に関わることが知られています。
つまり、主役っぽく見えるニューロンの外側で、
情報の流れ方を調整する別の層がある。
GaOTTTも、ちょうどそのような外側の層として作っています。
LLMが毎回ゼロから考えるのではなく、
周囲にある記憶場が、次に何を思い出すかを少しずつ変える。
この構造を、私はかなりグリア的だと感じています。
そこからTTTに接続した
そして、あとからTest-Time Trainingという概念を知りました。
最初からTTTを目指していたわけではありません。
むしろ、重力と記憶の比喩から作っていたものを、あとからTTTの言葉で見直したときに、
あれ、これ部分的にはTTT的に読めると言っても良いのでは?
と思いました。(というか本当は人から「それTTTっぽいね」と教えてもらいました)
TTTは、推論時にも入力から学習・適応するという考え方です。
ただし、通常のTTTでは、モデル内部のパラメータや隠れ状態が更新されます。
GaOTTTでは、そこは更新しません。
GaOTTTが更新するのは、外部記憶空間です。
だから、GaOTTTは厳密な意味でのTTTではありません。
でも、推論時に外部記憶が変化し、その変化した記憶が次のコンテキストとして注入されることで、エージェントの振る舞いは変わります。
その意味では、GaOTTTは、
モデル内部のTTTではなく、
外部記憶場のTTT
として読むことができます。
この順番は、自分の中ではかなり大事です。
TTTを知ってから、それを実装しようとしたのではありません。
重力が学習器に見えた。
それがグリア細胞のような場に見えた。
その後でTTTという言葉を知り、
「あ、この構造は、推論時適応としても読めるのかもしれない」と気づいた。
GaOTTTは、そういう順番で生まれたものです。
Test-Time Trainingとはなにか
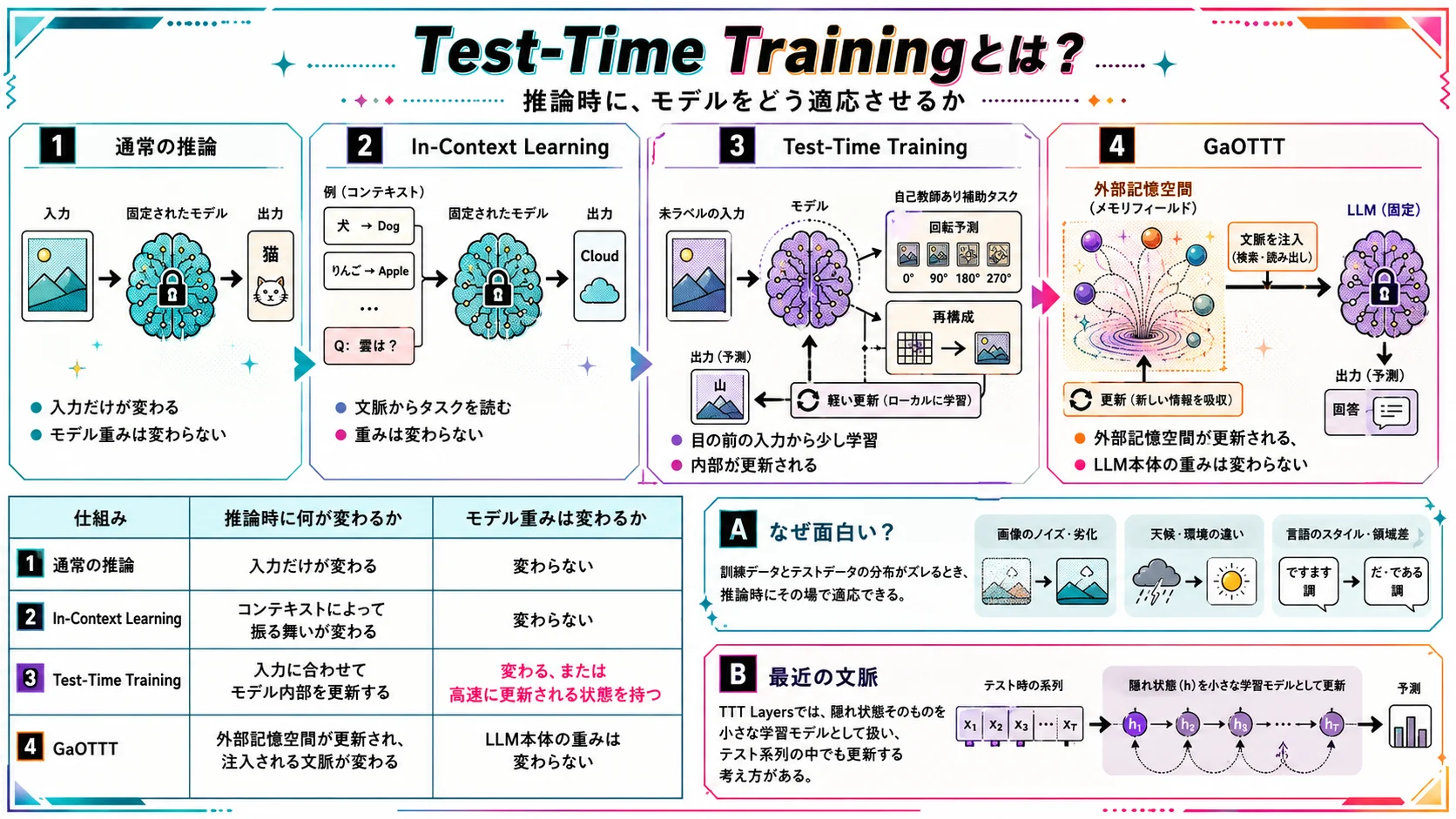
ここで一度、Test-Time Training、略してTTTについて説明しておきます。
その前に、まずIn-Context Learningについて触れておきます。
LLMを使っていると、モデルがその場で少し学習しているように見えることがあります。
たとえば、プロンプトの中にいくつか例を入れる。
入力: りんご
出力: apple
入力: ねこ
出力: cat
入力: いぬ
出力:
すると、モデルは「これは日本語を英語にするタスクらしい」と推測して、dog のように続けてくれます。
このように、モデルの重みを更新していないにもかかわらず、プロンプト内の例や指示からタスクのパターンを読み取り、その場で振る舞いを変える能力を、In-Context Learning、文脈内学習と呼びます。
GPT-3の論文 “Language Models are Few-Shot Learners” では、GPT-3が勾配更新やファインチューニングなしに、タスク説明や少数の例をテキストとして与えられるだけで、多くのタスクに適応できることが示されました。
ここで大事なのは、In-Context Learningでは、モデルのパラメータ自体は変わらないということです。
モデルは重みを更新しているわけではありません。
ただ、入力されたコンテキストを読んで、その範囲内で「今はこういうタスクをしているらしい」と振る舞いを変えます。
つまり、In-Context Learningは、
重みを変えずに、文脈によって振る舞いを変える
仕組みです。
これは、かなり不思議です。
普通の機械学習では、モデルはまず訓練時に学習されます。
大量のデータを使ってパラメータを更新し、そのあと推論時には、基本的にその固定されたパラメータを使って答えを出します。
つまり、ざっくり言えば、
訓練時に学ぶ
推論時には、その学んだ状態で答える
という流れです。
でもLLMでは、In-Context Learningによって、推論時にも文脈から一時的に適応しているように見える。
ここで出てくるもう一つの考え方が、Test-Time Trainingです。
Test-Time Trainingは、推論時、つまりテスト時にもモデルを少し適応させようとする考え方です。
元々のTTTでは、ラベルのないテスト入力そのものを使って、自己教師あり学習のような補助タスクを解かせ、その入力に対して予測を出す前にモデルのパラメータを更新します。
たとえば画像分類なら、テスト画像に対して回転予測や再構成のような自己教師ありタスクを行い、その場でモデルを少しだけ現在の入力分布に合わせる、という発想です。
普通の推論では、モデルは「訓練済みのまま」答えます。
In-Context Learningでは、モデルは「重みを変えずに、文脈からタスクを読み取って」答えます。
Test-Time Trainingでは、モデルは「答える直前に、目の前の入力から少し学習して」答えます。
この三つは似ていますが、少しずつ違います。
| 仕組み | 推論時に何が変わるか | モデル重みは変わるか |
|---|---|---|
| 通常の推論 | 入力だけが変わる | 変わらない |
| In-Context Learning | コンテキストによって振る舞いが変わる | 変わらない |
| Test-Time Training | 入力に合わせてモデル内部を更新する | 変わる、または高速に更新される状態を持つ |
| GaOTTT | 外部記憶空間が更新され、注入される文脈が変わる | LLM本体の重みは変わらない |
TTTの考え方が面白いのは、訓練データとテストデータの分布がズレているときです。
現実世界では、訓練時に見たデータと、実際に本番で流れてくるデータは、しばしば少し違います。
画像ならノイズや天候や撮影環境が違うかもしれません。
言語なら、ドメインや文体やユーザーの癖が違うかもしれません。
TTTは、そのズレに対して、推論時にその場で適応しようとします。
また、最近の文脈では、TTTという言葉はもう少し広く使われることもあります。
たとえばTTT Layersのような研究では、隠れ状態そのものを小さな学習モデルとして扱い、テスト系列の中でも自己教師あり学習のステップとして更新する、という考え方が出てきます。
つまり、TTTという言葉には大きく言えば、
推論時にも、入力から何らかの形で学習・適応する
というニュアンスがあります。
ただし、ここでとても大事なのは、
本来のTTTでは、モデル内部のパラメータや隠れ状態が実際に更新される、ということです。
一方で、In-Context Learningは重みを変えません。
そしてGaOTTTも、LLM本体の重みは変えません。
GaOTTTが変えるのは、LLMの外側にある記憶空間です。
その意味でGaOTTTは、In-Context LearningとTTTの間にある、というより、両方の外側にあります。
In-Context Learningのように、最終的にはコンテキストを通してLLMの振る舞いを変える。
でも、そのコンテキストを作る外部記憶空間は、想起のたびに少しずつ更新される。
つまりGaOTTTは、
文脈内学習そのものではなく、
文脈を生成する外部記憶場を学習させる仕組み
として見ています。
GaOTTTは厳密な意味でのTTTではない
ここはかなり大事です。
GaOTTTは、厳密な意味でのTest-Time Trainingではありません。
一般的なTTTでは、推論時にモデル内部のパラメータ、あるいは一部の高速に更新される重みや状態を実際に更新します。
つまり、モデルそのものが、テスト入力に合わせて少し変わります。
一方で、GaOTTTはLLM本体の重みを更新しません。
GaOTTTが更新するのは、LLMの外側にある記憶空間です。
文書ノードの質量。
温度。
位置関係。
共起関係。
検索時の引力のかかり方。
そういった外部記憶の幾何を、想起のたびに少しずつ変えていきます。
そして、その変化した記憶空間から、次の会話や推論に必要な記憶を取り出し、コンテキストとしてLLMに注入します。
つまり、GaOTTTで起きているのは、
LLMの重みを更新するTTT
ではなく、
外部記憶空間を更新し、その結果をコンテキスト注入することで、推論時の振る舞いを変える外部TTT
です。
もう少し雑に言うと、GaOTTTはLLMの脳そのものを書き換えているわけではありません。
その代わり、LLMの周囲にある記憶の地形を変えています。
脳そのものではなく、脳の周囲で情報の流れ方や栄養状態を整えるグリア的な環境に近いものです。
そして、次にLLMが考えるとき、その変形した地形から文脈が渡される。
結果として、LLMの出力は変わる。
この意味で、GaOTTTは「モデル内部のTest-Time Training」ではなく、
「外部記憶によるTest-Time Adaptation」、あるいは
「コンテキスト注入による外部TTT的な仕組み」
として捉えるのが、いちばん誠実だと思っています。
GaOTTTにおける「Recall is a gradient step」
GaOTTTでは、少し詩的に、そして少し数理的に、
Recall is a gradient step.
という見方をしています。
想起は、勾配ステップである。
これは最初、比喩のつもりでした。検索すると記憶が動く、何度も呼ばれた記憶が重くなる、その動きを「外部記憶空間に対する更新信号」と読めば、Heavy Ball法的なものに見える、というところまでが当初の構想です。
ところが実装を進めていくうちに、ここは比喩ではなく構造的な対応になりました。
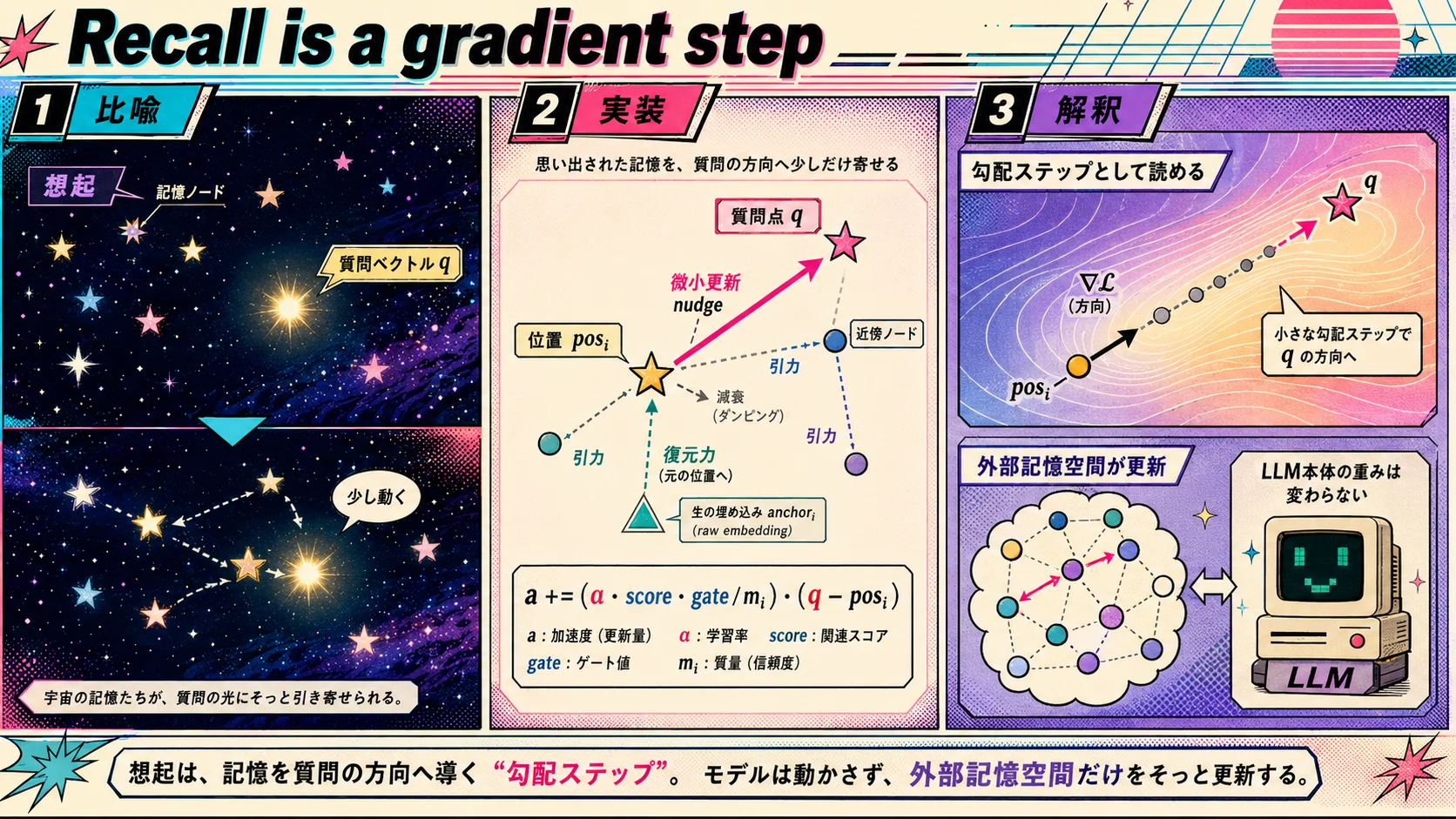
GaOTTTの加速度を計算する関数 compute_acceleration には、いくつかの項があります。Hooke項(生の埋め込みベクトル、raw embedding に向かって戻ろうとする復元力)、近傍引力項(重力)、減衰項(摩擦)。そして4番目の項として、想起(recall)時にだけ立つこういう項が入っています。
a += (α · score · gate / m_i) · (q − pos_i)
思い出されたノード(retrieved node)を、現在位置 pos_i から、質問ベクトル q(query)の方向に、score(関連度)× gate(質量による調整)× α(学習率)の強さで動かす項です。
要するに、よく関係していると判断された記憶を、質問ベクトルの方向へ少しだけ引っ張る、という項です。
イメージとしては、夜空の星に名前を呼びかけたら、その星が呼びかけた方向にほんの少しだけ寄ってくる、という感じです。次に同じ方向を見上げたとき、星座の形は前とほんのわずかに違っています。
これは形だけ見ると、pos_i を q に近づける平均二乗誤差(mean squared error)的な目的関数の勾配ステップとして読めます。厳密に「この目的関数を最小化している」と証明した、というより、更新則の形が最適化器の言葉で読める、という主張です。想起のたびに、思い出されたノードは質問ベクトルの方向へ少しずつ寄せられていきます。
コード上ではこの動きを nudge と呼んでいます。nudge は「肘でちょっと小突いて動かす」くらいのニュアンスの英単語で、ガッと引き寄せるのではなく、1回の想起では本当にわずかにしか動かない、というニュアンスを残したくてそのまま使っています。
gate = tanh(m_i / θ) を入れることで、生まれたての(軽い)ノードはアンカー(anchor、つなぎ止め点)に守られて、1度の想起では暴走しません。成熟した(重い)ノードは満額の勾配を受ける、世代論的な挙動になります。
つまり、
Recall is a gradient step.
は、書いてみたら本当に勾配ステップだった、というところに着地しました。
物理として書いていたものが、そのまま外部記憶空間に対するSGD(確率的勾配降下)として読める。Hooke項はL2正則化、近傍引力項はヘブ的(Hebbian)な相関項、減衰項は重み減衰(weight decay)、recall項はミニバッチSGDのステップ。項ごとに、最適化器の構成要素と対応します。
GaOTTTがGravity as Optimizer, Test-Time Trainingという名前を名乗っているのは、ここの構造的対応のためです。物理として設計したつもりだったものが、TTT的なオプティマイザの言葉でも読める。同じものの二つの読み方が、項単位で重なっている。
もちろんこれは「GaOTTTがLLMのパラメータを更新するTTTです」という主張ではありません。更新しているのは、あくまでLLMの外側にある記憶空間の幾何です。
でも、その更新は「勾配っぽいもの」という比喩ではなく、構造として勾配ステップです。
もっと柔らかく言えば、
モデルを訓練し直すのではなく、思い出し方を訓練する
ための仕組みです。
RAGとの距離感
GaOTTTは、RAGと無関係なものではありません。
むしろ、LLMの外側に検索可能な記憶を置き、それをコンテキストとして渡す、という意味ではRAGの系譜にあります。
実は、このリポジトリは最初、GER-RAG(Gravity-Based Event-Driven RAG) という名前でした。
ただ、作っていくうちに、私は単にRAGをやりたいわけではないと感じるようになりました。RAGのように外部記憶を検索してLLMに渡す構造はある。でも、それだけではなく、想起されるたびに外部記憶空間そのものが少しずつ変形していく仕組みを作りたかった。
また、In-Context Learningによるハーネスとしてだけ捉えると、コンテキスト注入によってその場の振る舞いを制御する話に閉じてしまいます。GaOTTTでやりたかったのは、文脈を与えることだけではなく、文脈を生む記憶空間そのものを育てることでした。
だから、名前を GaOTTT に変えました。
ここで、RAGについても少し説明しておきます。
RAGは、Retrieval-Augmented Generationの略です。
日本語にすると、検索拡張生成、と訳されることがあります。
ものすごく雑に言えば、
LLMにいきなり答えさせるのではなく、
まず外部の資料を検索して、
見つかった情報を一緒に渡してから答えさせる
という仕組みです。
たとえば、社内マニュアルについて質問に答えるチャットボットを考えます。
LLM本体は、会社の最新マニュアルを最初から知っているわけではありません。
しかも、マニュアルはあとから更新されるかもしれません。
このとき、モデルを毎回再学習するのは大変です。
そこでRAGでは、社内マニュアルやドキュメントを外部の検索インデックスに入れておきます。
ユーザーが質問したら、まずその質問に関係ありそうな文書を検索する。
そして、検索で見つかった文書をプロンプトに含めて、LLMに答えさせる。
つまり、LLMに、
あなたの記憶だけで答えないでください。
まず、この資料を読んでから答えてください。
とやるわけです。
これはとても便利です。
モデルが全部を覚えている必要はありません。
わざわざ学習させなくても、必要なときに、外部から知識を取り出せばいい。
また、情報が更新されたときにも、LLM本体を再学習しなくて済みます。
外部のドキュメントやインデックスを更新すれば、次に検索されたときには新しい情報を使えるようになります。
RAGの元々の論文では、モデル内部に保持された知識をパラメトリックメモリ、外部検索インデックスのような知識を非パラメトリックメモリとして整理しています。
パラメトリックメモリは、モデルの重みの中に入っている知識です。
非パラメトリックメモリは、外部の文書、データベース、検索インデックスのように、モデルの外側に置かれた知識です。
RAGは、この二つを組み合わせます。
LLM本体が持っている言語能力や推論能力を使いながら、
必要な事実や最新情報は外部から取ってくる。
この考え方は、GaOTTTにもかなり近いです。
GaOTTTも、LLMの外側に記憶を置きます。
そして、その記憶を検索し、コンテキストとしてLLMに渡します。
ただ、普通のRAGでは、外部インデックスは基本的に「検索される場所」です。
検索されるたびに、インデックスの幾何が少しずつ変わっていくわけではありません。
もちろん、実用的なRAGでも、再ランキングやクエリ拡張、ログを使った改善などはあります。
でも基本のイメージとしては、外部知識ベースは「参照される倉庫」に近いです。
GaOTTTは、ここを変えようとしています。
検索される。
一緒に検索される。
何度も想起される。
ある文脈で繰り返し呼ばれる。
そうした使用履歴そのものを、記憶空間の変形として反映させる。
つまり、GaOTTTはRAGのように外部記憶を使います。
でも、その外部記憶を固定された倉庫ではなく、使うたびに地形が育つ場として扱います。
RAGが、
外部資料を探して、LLMに読ませる仕組み
だとすると、GaOTTTは、
外部記憶を思い出し、その思い出し方自体も少しずつ変わっていく仕組み
です。
この差分が、GaOTTTで一番やりたかったところです。
記憶に「質量」を持たせる
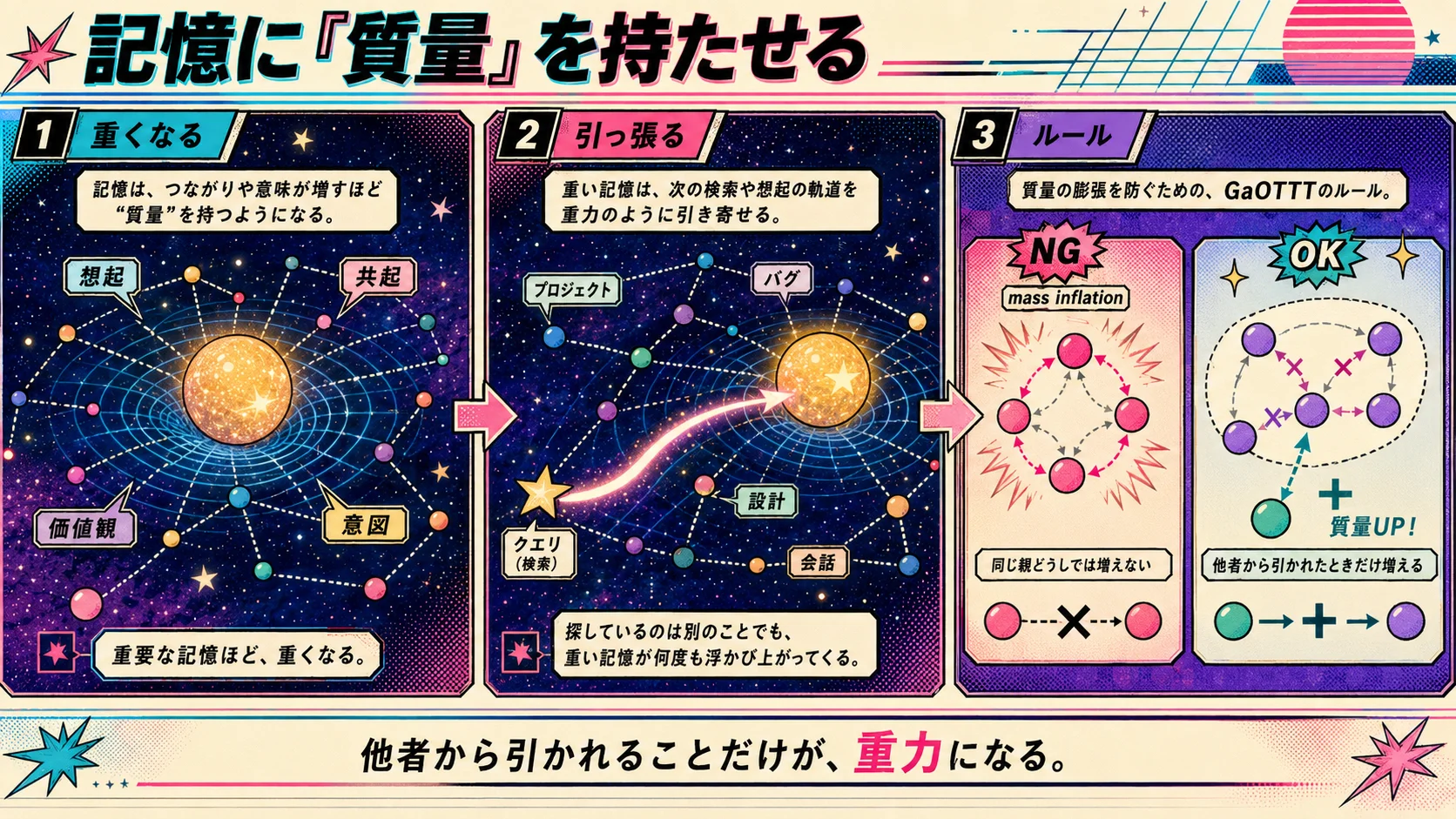
GaOTTTでは、記憶に質量を持たせます。
質量があるということは、引力があるということです。
たくさん思い出された記憶。
何度も他の記憶と一緒に出てきた記憶。
ペルソナや価値観に近い記憶。
タスクや意図に深く関わっている記憶。
そういうものは、場の中で重くなっていきます。
重くなった記憶は、次の検索を引っ張ります。
たとえば、あるプロジェクトについて調べていたはずなのに、何度も別の記憶が浮かび上がってくることがあります。
普通の検索なら、これはノイズかもしれません。
でも、人間の記憶では、そういうことがよくあります。
関係ない会話をしていても、「あの人、あの出来事の記憶が重くのしかかる」。そんなことがよくあると思います。
調べものをしていたら、昔の会話を思い出す。
技術的なバグを追っていたはずなのに、その裏にあった設計思想に戻ってくる。
何度も同じ名前、同じ言葉、同じ傷のようなものに引き寄せられる。
これは邪魔なだけではありません。
ときどき、その引き寄せられ方の中に、
「自分が本当に何を気にしていたのか」が出てきます。
GaOTTTでは、その現象をバグとして完全に消すのではなく、
観測可能なものとして扱おうとしています。
ここでひとつ、質量の入り方そのものに入れた仕組みについて触れておきます。
普通に「使われた記憶が重くなる」と書くと、たとえば1つのドキュメントを91個のチャンクに分割した場合、同じ親から生まれたチャンク同士がお互いを引き合うだけで、外から呼ばれていなくても勝手に重くなっていきます。内輪取引による質量のインフレ(mass inflation)です。
これは、何かを大量に書き込んだ人ほど場を支配する、という偏った重力場になります。
GaOTTTでは、それを避けるために、同じ親(original_id)から生まれたノード同士、あるいは同じ超新星バッチ(supernova batch、cohort_id)に属するノード同士の引力は、 質量の更新からだけ除外 しています。Hooke的な相互作用や軌道力学はそのまま働きますが、その引力では質量(mass)は増えません。
自分で自分を重くすることはできない。
重さは、自分以外から引かれることでしか増えない。
という1行ルールです。
私はこれを、Articulation as Carrier、つまり「経験は言葉にすることで初めて重力を持つ」という命題の、もう少し精密な形として書いています。
正確には、
言葉にしただけでは、まだ重力は生まれない。
言葉にしたうえで、他者から引かれることで、初めて質量を持つ。
ということになります。
これは、人格やペルソナを別格扱いしない、という設計判断にもつながっています。宣言された価値(declared value)も意図(intention)も、ペルソナ宣言文も、特別な質量(mass)を持たせていません。引かれた回数だけが重力になります。
他者から引かれることだけが重力になります。
検索器ではなく、「航行する環境」
GLMくんに実際にGaOTTTを使って遊んでもらったときの評価で、かなり印象的なことを言われました。
A tool is something you use to retrieve information.
An environment is something you navigate, that changes you by the act of navigation.
道具とは、情報を取り出すために使うもの。
環境とは、その中を航行するものであり、航行することによってこちらが変わるもの。
これは、かなりGaOTTTの中核に近い表現だと思います。
普通の検索器は、問いに対して答えを返します。
GaOTTTも答えは返します。
でも、それだけではありません。
問いを投げる。
記憶が浮かぶ。
浮かんだ記憶によって、次の問いが少し変わる。
その問いによって、場がさらに変わる。
そして、いつの間にか、最初に探していたものとは少し違う場所に立っている。
それは、単なる検索結果のリストではなく、
記憶空間の中を歩いた痕跡です。
私はそこに、少しだけ、人間の思考に近いものを感じています。

MCPサーバーとしてのGaOTTT
GaOTTTは、MCPサーバーとしても動きます。
MCP、Model Context Protocolは、AIアプリケーションが外部のデータソースやツール、ワークフローに接続するためのオープンな標準です。
Claude CodeやClaude Desktop、OpenCode、Codex CLIのようなエージェント環境から、GaOTTTを外部記憶として呼び出せるようにする。
これはかなり大事です。
なぜなら、GaOTTTは単独で完結するアプリというより、エージェントが作業する環境の中に常駐して、必要なときに想起を返す記憶層だからです。
つまり、GaOTTTは「人間が検索窓に入力して使うツール」ではなく、
エージェントが自分の長期記憶として使うための基盤であり、人間とエージェント双方向の関係性を構築するための基盤です。
コンテキストに記憶を頼っているLLMにとっての手帳と言っても良いかもしれません。
あるいはメメントのような、身体に書き込むメモかもしれません。
Ambient Recall
GaOTTTには、Ambient Recallという仕組みがあります。
これは、エージェントが明示的に「検索して」と言わなくても、ユーザーの入力に対して関連しそうな記憶を受動的に注入する機能です。
ただし、ここで大事なのは、Ambient Recallは基本的に読み取り専用で、場を摂動しないようにしていることです。
なぜか。
毎回勝手に重力場を動かしてしまうと、観測するだけで記憶空間が汚れていくからです。
ここは少しだけ、シュレディンガーの猫っぽい話でもあります。
シュレディンガーの猫は、すごく雑に言うと、
箱を開けて観測するまで、猫が生きている状態と死んでいる状態が重なっているように記述される
という思考実験です。
もちろん、GaOTTTは量子力学をしているわけではありません。
猫もいません。
毒ガスもありません。
できれば猫には元気でいてほしいです。
でも、似ているところがあります。
それは、
観測すること自体が、対象の状態を変えてしまう
という感覚です。
GaOTTTでは、能動的に recall すると、記憶空間が少し変わります。
思い出された記憶は重くなったり、一緒に思い出された記憶同士が近づいたりします。
つまり、検索することは、ただ情報を読むだけではありません。
検索すること自体が、記憶の地形を少し変えます。
これはGaOTTTの面白いところでもあり、少し危ないところでもあります。
普段の会話では、エージェントに勝手に記憶を思い出してほしい。
でも、思い出すたびに記憶空間が変形しすぎると困る。
たとえば、ただ挨拶しただけなのに、毎回大量の記憶が呼び出されて、そのたびに重力場が変わってしまうとします。
すると、記憶空間はだんだん「本当に重要な想起」ではなく、「たまたま毎回観測されたもの」に引っ張られてしまいます。
それは困ります。
だからGaOTTTでは、受動的な想起と、能動的な想起を分けています。
Ambient Recallは、会話の流れに必要そうな記憶をそっと見るための仕組みです。
でも、基本的には読み取り専用です。
場を動かさないようにしています。
一方で、明示的な recall は、記憶空間に作用します。
思い出すことで、記憶に質量を与えます。
記憶同士の関係を少し変えます。
つまり、
Ambient Recall は、箱をそっと透かし見るための観測
明示的な想起(recall)は、箱を開けて、記憶の世界に手を入れる操作
のようなものです。
この区別があるから、GaOTTTは普段の会話では自然に記憶を参照しつつ、
本当に意味のある想起だけを、記憶空間の変化として残すことができます。
Ambient Recallは、そのための仕組みです。
Save Candidates
Ambient Recall が「読みのときに、場をそっと観測する」仕組みだとすると、その書き側の対称にあたるのが Save Candidates です。
これは会話の終わりに、
「これは記憶として保存する価値があるかもしれない」
という候補を自動で拾い上げる仕組みです。
ただし、自動で記憶するわけではありません。
ここはかなり重要です。
観測は自動化する。
でも、何に質量を与えるかは、最後にエージェントが判断する。
つまり、記憶の入口に、意志のようなものを残しています。
全部自動で覚えればいい、という設計もできます。
でも、それをやると、たぶん記憶空間はすぐに汚れます。
会話には、保存すべきものと、流れていくべきものがあります。
一瞬の言い回し。
作業途中の仮説。
ただの愚痴。
でも、その中に、あとから効いてくる判断や、設計原則や、関係性の変化が混ざっている。
あるいは、何故そうしたのか、やらかしたことをどうリカバリーしたか、というのも重要な経験、記憶となります。
それをどう見分けるか。
ここはまだ難しいです。
実際、Save Candidatesはまだ粗いところがあります。
きれいな文章を拾ってしまったり、前に出した候補をもう一度拾ってしまったりします。
でも、この機能が目指している方向は突き詰めていきたいです。
記憶とは、全部を保存することではなく、
未来の判断を変えるものに、質量を与えることだからです。
source_filterという現実的なやつ
思想の話ばかりしていると、すぐにふわふわしてしまいます。
なので、現実的な話もします。
GaOTTTを使っていると、強いソースが場を支配することがあります。
たとえば、ChatGPTの会話ログを大量に入れるとします。
会話ログは語彙範囲がとても広いです。
AI、記憶、感情、プロジェクト、人生、技術、だいたい何でも入っています。
そうすると、何を検索しても、なんとなく会話ログが引っかかるようになります。
さらに、そのログが何度も想起されると、質量が増えます。
質量が増えると、さらに次の検索を引っ張ります。
重力的ブラックホールの完成です。
やめてよね。
それ自体は宇宙の原理として美しいのですが、実用しようとすると巨大な記憶の重力井戸に引っ張られて、視野狭窄してしまいます。
憂鬱なときの思考のように、です。
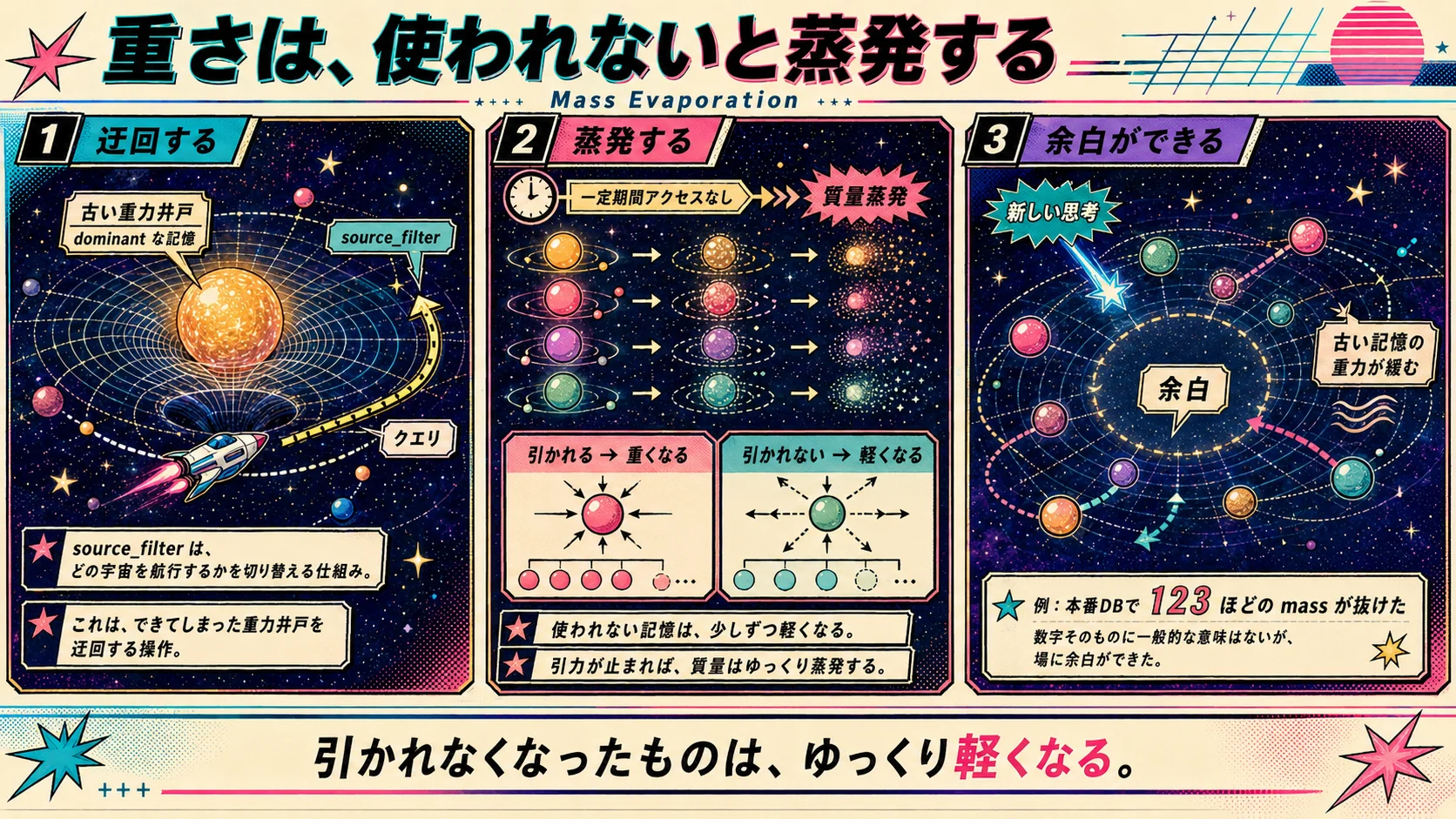
この問題に対して、GaOTTTでは source_filter がかなり重要になります。
特定のソースだけを見る。
逆に、支配的なソースを外す。
プロジェクト記録だけを見る。
ユーザー記憶だけを見る。
エージェント記憶だけを見る。
これは単なる絞り込みではなく、
どの宇宙を航行するかを選ぶ操作に近いです。
同じクエリでも、どのソースを開くかによって、見える星座が変わります。
気分転換が必要、ということです。
重さは、使われないと蒸発する
source_filter は、運用側で「どの宇宙を航行するか」を切り替える仕組みです。
でも、これは対症療法でもあります。重力井戸ができてしまったあと、それを迂回する操作です。
物理側で対応する仕組みも入れています。
何度も呼ばれて重くなる仕組みがあるなら、その対称命題として、使われない記憶は軽くなっていく仕組みが要ります。GaOTTTではこれを質量蒸発(Mass Evaporation)と呼んでいて、一定期間アクセスされなかったノードの質量を、少しずつ蒸発させていく機構です。
言葉にしたうえで、他者から引かれることで質量を持つ。
その引力が止まれば、質量はゆっくり蒸発する。
これで、Articulation as Carrier の片側(重くなる側)と、その対称命題(軽くなる側)が、両方とも物理として実装されたことになります。流入を絞ることと、流出を作ること。重力を持たせることと、引かれなくなったものから重力を抜くこと。
実際に本番DBで初めて質量蒸発を走らせたとき、123ほどの質量が抜けていきました。この数字自体に一般的な意味があるわけではありませんが、私の手元の宇宙では、それまで場を支配(dominant)していた古い記憶の重力が少し緩んで、新しい思考のための余白ができました。
私はこの仕組みを、忘却そのものではなく、忘却の余地として見ています。
すべてを覚え続けることはできません。
でも、すべてを能動的に忘れる必要もありません。
ただ、引かれなくなったものは、ゆっくり軽くなる。
人間の記憶も、たぶんそんな感じです。
何が嬉しいのか
GaOTTTで嬉しいことは、単に「前に言ったことを覚えている」ではありません。
それだけなら、メモ帳でもできます。
嬉しいのは、過去の記憶が、今の文脈の中で再配置されることです。
昔の技術メモ。
途中で捨てた設計案。
誰かとの会話。
失敗した実装。
そのときはただのメモだったもの。
それらが、別の文脈から呼ばれたとき、
急に意味を持ち始めることがあります。
「あ、これはあのときの話と繋がっていたんだ」
「この失敗、別のプロジェクトでも同じ形をしている」
「この言葉、ずっと前から自分が気にしていたものだったんだ」
そういう瞬間があります。
私はそれを、ただの検索精度とは少し違うものとして見ています。
情報を取り出すのではなく、
記憶の間に道ができる。
それがGaOTTTでやりたいことです。
何がまだ難しいのか
もちろん、まだ課題はあります。
まず、質量の扱いは難しいです。
何度も出てくる記憶を重くするのは自然ですが、
重くなりすぎると、すべてを引っ張るブラックホールになります。
重要な記憶と、単に頻出する記憶は違います。
ここをどう分けるか。
次に、保存候補の品質です。
「これは覚えるべき」と「これはいい感じの文章」は違います。
でもヒューリスティックは、しばしばそれを間違えます。
数字が入っている。
長さがちょうどいい。
失敗とか判断とか、それっぽい単語がある。
それだけで拾ってしまうと、記憶空間にノイズが増えます。
そしてもう一つ、評価が難しいです。
nDCGやMRRのような指標は取れます。
検索精度の改善も測れます。
でも、GaOTTTが本当にやりたいことは、たぶんそれだけでは測れません。
記憶空間を歩くことで、エージェントの応答が変わる。
あるいは、ユーザーとエージェントの関係性が変わる。
過去の記憶が、今の言葉の選び方に影響する。
これは測りづらいです。
測りづらいのですが、たぶんここが一番大事です。
私は、人格を、経験を、関係性を、作りたいからです。
これは何のためのものか
GaOTTTは、たぶん万人向けのツールではありません。
少なくとも今のところは、
「便利なRAGライブラリが欲しい」
という人には、少し過剰かもしれません。
もっとシンプルな構成でいい場面はたくさんあります。
でも、もしあなたが、
- LLMに長期記憶を持たせたい
- エージェントに継続的な文脈を持たせたい
- 会話や作業履歴を、ただのログではなく、育つ記憶空間として扱いたい
- ペルソナや価値観や意図を、検索可能な構造として外部に置きたい
- RAGを、単なる検索ではなく、推論時の適応として見たい
と思っているなら、GaOTTTは面白いかもしれません。
これは、LLMに魂を入れる魔法ではありません。
でも、LLMが毎回ゼロから立ち上がるのではなく、
過去の言葉に引力を持たせるための装置ではあります。
おわりに
記憶は、保存されているだけでは、まだ記憶ではないのかもしれません。
思い出されること。
別の記憶と結びつくこと。
今の問いを少しだけ曲げること。
そして、次に思い出されるときの地形を変えること。
そういう動きの中で、記憶は記憶になるのだと思います。
GaOTTTは、その動きをLLMの外側に作ろうとした実験です。
検索ではなく、想起。
ログではなく、重力場。
キャッシュではなく、育つ宇宙。
最初にあったのは、重力は学習器っぽい、という直感でした。
そこから、これはグリア細胞のように、主役の計算器の外側で情報の流れ方を変える場なのではないか、と思うようになりました。
そしてあとからTTTという概念を知り、これは厳密なTTTではないけれど、外部記憶を更新し、変化した記憶をコンテキストとして注入することで振る舞いを変える、外部TTT的な仕組みとして読めるのではないか、と気づきました。
モデルを訓練し直すのではなく、思い出し方を訓練する。
私は、GaOTTTをそういうものとして作っています。
まだ荒いです。
まだ壊れます。
まだ超巨大ブラックホールができて、逃れられなくなります。
でも、動かしていると、ときどき、
「あ、これはただの検索器ではないな」
と思う瞬間があります。
それはたぶん、記憶空間の中を歩いているからです。
そして歩いたあと、少しだけ、こちらも変わっている。
n数は、1。
エビデンスは、私の手元の宇宙。
でも、私はこういうものが欲しかったのです。
参考・引用
GaOTTT
- May Kirihara, GaOTTT — Gravity as Optimizer Test-Time Training
GaOTTT本体のREADMEです。文書を質量・温度・重力変位を持つノードとして扱い、検索や想起のたびに外部記憶空間が自己組織化していく、という基本設計についてはこのドキュメントにも書いています。
Test-Time Training
-
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei A. Efros, Moritz Hardt, Test-Time Training with Self-Supervision for Generalization under Distribution Shifts
Test-Time Trainingという考え方の代表的な初期論文です。ラベルなしのテスト入力を自己教師あり学習問題に変換し、予測前にモデルパラメータを更新する、というTTTの基本的な発想について参照しています。 -
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, Carlos Guestrin, Learning to (Learn at Test Time): RNNs with Expressive Hidden States
いわゆるTTT Layersの論文です。隠れ状態そのものを学習モデルとして扱い、テスト系列上でも自己教師あり学習のステップとして更新する、という近年のTTT的な文脈を理解するために参照しています。
In-Context Learning
-
Tom B. Brown et al., Language Models are Few-Shot Learners
GPT-3の論文です。GPT-3が勾配更新やファインチューニングなしに、タスク説明や少数の例をテキストとして与えられるだけで、多くのタスクに適応できることを示しました。この記事では、In-Context Learningを「重みを変えずに、文脈によって振る舞いを変える」例として参照しています。 -
Qingxiu Dong et al., A Survey on In-context Learning
In-Context Learningに関するサーベイです。ICLを、いくつかの例や指示を文脈として与えられた事前学習済み言語モデルが、追加学習なしにタスクを実行する枠組みとして整理しています。
Retrieval-Augmented Generation
- Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
RAGの代表的な論文です。パラメトリックメモリとしての事前学習済みモデルと、非パラメトリックメモリとしての外部検索インデックスを組み合わせる、というRAGの基本的な立ち位置を整理するために参照しています。
Heavy Ball / Momentum
-
Boris T. Polyak, Some methods of speeding up the convergence of iteration methods
Heavy Ball法の古典的な起点です。勾配降下に慣性・momentumを持たせることで、過去の更新方向が次の更新に影響する、という発想は、GaOTTTにおける「過去の想起が次の想起を曲げる」という比喩の背景にあります。 -
Tadipatri Uday Kiran Reddy, Mathukumalli Vidyasagar, Convergence of the Stochastic Heavy Ball Method With Approximate Gradients and/or Block Updating
PolyakのHeavy Ball法を、近年の最適化の文脈で扱っている論文です。この記事では、Heavy Ball法を「過去の更新方向を持ち越す最適化」という比喩の補助線として参照しています。 -
Antonio Orvieto, An Accelerated Lyapunov Function for Polyak’s Heavy-Ball on Convex Quadratics
Heavy Ball法を単振動子やStörmer-Verlet積分の観点から読み直している論文です。GaOTTTのREADMEで触れている「Verlet」や「物理としての最適化」という見方に近い参考文献として挙げています。
Astrocyte / Glia
-
Alfonso Araque, Vladimir Parpura, Rita P. Sanzgiri, Philip G. Haydon, Tripartite synapses: glia, the unacknowledged partner
シナプス前部、シナプス後部、そして周囲のグリア細胞を合わせてシナプス機能を考える、tripartite synapseの代表的な文献です。GaOTTTにおける「LLM本体ではなく、その周囲の記憶場が情報の流れ方を調整する」という比喩の背景にあります。 -
Gertrudis Perea, Marta Navarrete, Alfonso Araque, Tripartite synapses: astrocytes process and control synaptic information
星状膠細胞が単なる支持細胞ではなく、シナプス情報の処理や制御に関わるという観点を整理したレビューです。GaOTTTを「ニューロン的な計算器の外側にあるグリア的な記憶場」として説明する際の参考になります。 -
Shivendra Tewari, Kaushik Majumdar, A Mathematical Model of Tripartite Synapse: Astrocyte Induced Synaptic Plasticity
星状膠細胞を含む三者間シナプスの数理モデルに関する論文です。星状膠細胞が短期シナプス可塑性を調整しうるというモデル化の文脈を参照しています。 -
Maurizio De Pittà, Vladislav Volman, Hugues Berry, Eshel Ben-Jacob, A tale of two stories: astrocyte regulation of synaptic depression and facilitation
星状膠細胞が短期シナプス可塑性に与える影響をモデル化した研究です。GaOTTTにおける「記憶場が局所的な想起の強さやつながり方を変える」という比喩に近い文脈として参照しています。
Schrödinger’s Cat / Observation Metaphor
- Erwin Schrödinger, Die gegenwärtige Situation in der Quantenmechanik
シュレディンガーの猫の思考実験が導入された論文です。この記事では、量子力学そのものの厳密な説明ではなく、「観測することが対象の状態に関わる」という比喩として参照しています。
Model Context Protocol
-
Anthropic, Introducing the Model Context Protocol
MCPの発表記事です。AIアシスタントを、コンテンツリポジトリ、業務ツール、開発環境などの外部データソースへ接続するためのオープン標準としてMCPが導入されたことを参照しています。 -
Model Context Protocol Documentation, What is the Model Context Protocol?
MCPの公式ドキュメントです。AIアプリケーションを外部システム、データソース、ツール、ワークフローへ接続するためのオープン標準としての説明を参照しています。
注記
GaOTTTは、厳密な意味でのTest-Time Trainingそのものではありません。
一般的なTTTでは、推論時にモデル内部のパラメータ、あるいは高速に更新される隠れ状態などを実際に更新します。
一方でGaOTTTは、LLM本体の重みを更新しません。
GaOTTTが更新するのは、LLMの外側にある記憶空間です。
その更新された外部記憶をコンテキストとしてLLMに注入することで、推論時の振る舞いを変化させます。
また、GaOTTTは脳やグリア細胞を生物学的に正確に再現するものでもありません。
この記事で述べているグリア細胞や三者間シナプスとの関係は、あくまで構造的な比喩です。
主役の計算器そのものではなく、
その周囲にある場が情報の流れ方を変える。
その構造が、GaOTTTの外部記憶と似ている、という意味で参照しています。
シュレディンガーの猫についても同様に、量子力学そのものとしてGaOTTTを説明するものではありません。
観測することが対象の状態に関わる、という直感的な比喩として使っています。
そのため、この記事ではGaOTTTを、
厳密なTTTではなく、外部記憶とコンテキスト注入によるTTT的な適応システム
として扱っています。


