
これはなに?
え、今さら Attention Is All You Need?と言われそうですが、
最新のアーキテクチャや論文を読むにしても、基本はTransformerの変形であることが多いです。
まずは基礎を抑えないと何事もふわふわ理解になってしまいますので、
今回から、機械学習まわりの論文を、勉強も兼ねて少しずつ読んでいこうと思います。
記事のネタにするとモチベーションにもなるしね。
改めて、最初に読むのは、
Attention Is All You Need
という論文です。
名前だけはだいたいみんな知っている、やたら有名なやつです。
Transformerの元論文であり、今のLLMのかなり大きな源流になっている論文です。
GPTも、BERTも、T5も、最近の多くの言語モデルも、かなり大きく言えばこのTransformerの系譜にあります。
タイトルをニュアンスも含めて訳すと、
ぶっちゃけ、Attentionしかいらなくね?笑
みたいな感じです。
強い。
かなり強いタイトルです。
「いや、そんなこと言って大丈夫?」という感じもしますが、結果としてこの論文は本当にその後の自然言語処理の流れを大きく変えました。
この記事では、Attention Is All You Needを読みながら、
- Transformerは何をやめたのか
- Attentionとは何なのか
- Query / Key / Valueとは何なのか
- 数式は何をしているのか
- FFNやLayerNormは何をしているのか
- RoPEやSwiGLUなど、最近のLLMアーキテクチャにどうつながるのか
を、なるべくゆるく整理していきます。
数式も少し出します。
でも、数式を完全に証明するというより、
この式は、何をやっている気持ちなのか
を見ていく感じにします。
これは、最近のLLMアーキテクチャを読むための前段としてのTransformer入門です。
いきなりQwenやDeepSeekのconfigを見に行くと、RoPE、RMSNorm、SwiGLU、MoE、FlashAttentionなどが一気に出てきて、何が何だか分からなくなります。
なのでまず、元のTransformerを見ます。
地図を読む前に、地図記号を覚えるような回です。楽しいよ。
アーキテクチャ図を見てみる
![]()
* Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin, Attention Is All You Need より引用
……これだけ見ても何がなんだかよくわかりません。
私も何故みんなこの図を理解できるのかわかりませんでしたが、
各パーツの意味を知ると、途端に「あー、そういうことね」とわかるようになりました。
だから、 まずは「地図記号」を覚える必要がある のです。
何がすごかったのか
さっきの図は一旦置いておいて、
この論文のすごさをものすごく雑に言うと、
今まで文章を前から順番に読んでたけど、順番に読むのをやめた
というイカれた発想にあります。
もちろん、完全に順番を無視したわけではありません。
あとで出てくる「位置エンコーディング(Positional Encoding)」によって、文章内の位置情報はちゃんと入れています。
でも、基本の発想としては、RNNのように、
1単語目を読む
2単語目を読む
3単語目を読む
前の状態を受け取りながら次へ進む
という処理から離れました。
それまでの自然言語処理では、文章は「時系列」として扱われることが多かったです。
文章は前から後ろへ流れる。
だからモデルも前から後ろへ読む。
自然ですね。
人間も文章を読むとき、だいたい前から読みます。
いきなり全部の単語を一斉に見て、空中に意味の星座を作る、みたいな読み方はしません。
少なくとも表面上は。
でもTransformerは、どちらかというと文章を、
単語たちが互いに関係を持っている場
として扱います。
「この単語は、文中のどの単語を見れば意味が決まるのか」
「この単語は、どの単語と強く関係しているのか」
「いまこの位置にいるトークンは、他のどのトークンから情報をもらうべきなのか」
そういう関係を、一気に計算します。
文章を、一本のヒモとしてではなく、関係の網として見る仕組み。
よくわからないけれど、どういうことなんでしょう。
RNNをやめたかった
Attention Is All You Needが出た当時、系列データを扱うモデルとしてはRNN、LSTM、GRUなどがよく使われていました。
RNNは、ざっくり言うと「前の状態を覚えながら次へ進む」モデルです。
たとえば、
私は昨日、駅前のカフェで友達と話した。
という文を読むとき、RNNは前から順番に処理していきます。
「私は」を読む。
その状態を持って「昨日」を読む。
その状態を持って「駅前の」を読む。
さらに「カフェで」を読む。
こうやって、文章の情報を状態に折りたたみながら進みます。
これは直感的にはわかりやすいです。
でも問題があります。
順番に処理するので、並列化しにくいのです。
GPUは「同じような計算を大量に一気にやる」のが得意です。
でもRNNは、
ひとつ前の計算が終わらないと、次の計算に進めない
という構造を持ちます。
工場のライン作業のようなものです。前の作業が終わらないと、次の作業ができない。つらい。
一方でTransformerは、文中の各トークン同士の関係をまとめて計算できます。
こちらは、会議室にいる全員が一斉に「誰を見るべきか」を決める感じです。
一人ずつ順番に発言する会議ではなく、
全員が同時にガン(視線)を飛ばし合って、
「こいつの話は重要そう」
「この人とは関係が薄そう」
「こいつ、さっきから主語を握ってやがるな」
と重みづけしていく。
だいぶ治安の悪い会議です。
でも、GPUにとってはかなり都合がいい。
この並列化しやすさが、あとからモデルを巨大化していくときにかなり効いてきます。
Attentionとはなにか
Attentionは、日本語では「注意機構」と訳されることがあります。
ただ、「注意」と言われてもよくわかんねえですね。
ここでは、
いま処理しているトークンが、他のどのトークンをどれくらい見るかを決める仕組み
くらいに考えるとよさそうです。
たとえば、こういう文を考えます。
猫はソファの上で丸くなった。なぜなら、それは眠かったからだ。
この 「それ」 は何を指しているのでしょうか。
たぶん「猫」 です。
「ソファ」ではありません。
ソファは眠くなりません。
たぶん。
少なくとも一般的なソファは。
このとき、「それ」というトークンの意味を考えるには、文中の「猫」を見る必要があります。
つまり、「それ」は「猫」にAttentionを向ける必要がある。
このように、ある単語の意味は、その単語だけでは決まらないことが多いです。
周囲の単語。
離れた単語。
前に出てきた名詞。
文全体の構造。
そういうものを参照して、はじめて意味が決まります。
Attentionは、この「どこを見ればよいか」をニューラルネットワークの中で計算できるようにした仕組み です。
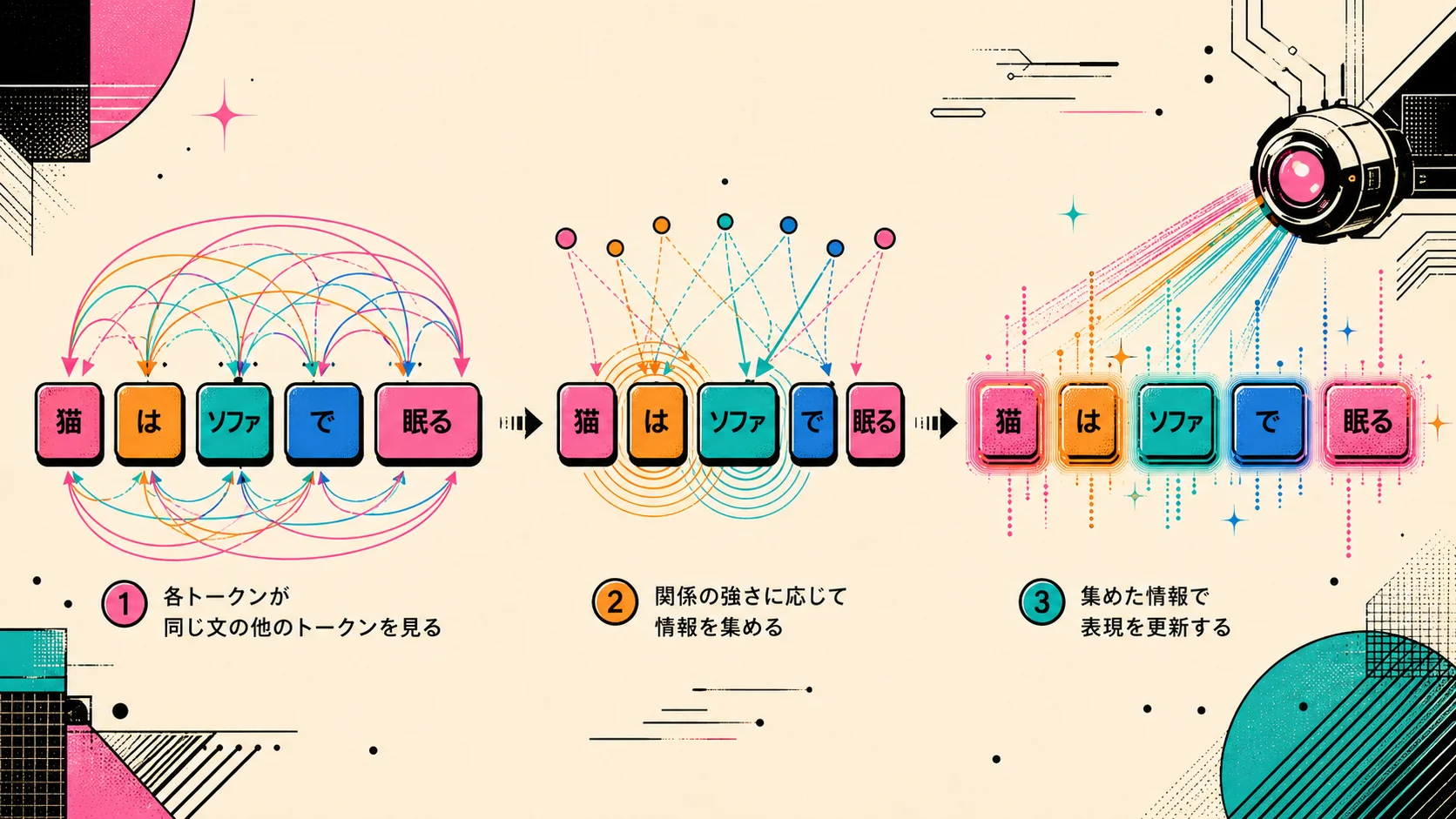
Self-Attentionとはなにか
Transformerで重要なのは、特に Self-Attention です。
Self-Attentionは、入力された系列の中で、各トークンが同じ系列の他のトークンを見る仕組みです。
つまり、自分たちの中で互いに参照し合うAttentionです。
文がある。
その中の各トークンが、他のトークンを見る。
見た結果を使って、自分の表現を更新する。
これを全トークンで行います。
イメージとしては、文章内の全単語が、いったん会議室に集められる感じです。
「私はこの文の中で、誰と関係が深いですか?」
「私はどの単語から意味をもらえばいいですか?」
「この代名詞は誰を指していますか?」
「この動詞の主語は誰ですか?」
全員が同時にそれをやります。
そして、それぞれのトークンが、自分に関係ありそうなトークンから情報を集めて、新しい自分の表現を作る。
これがSelf-Attentionです。
Query / Key / Value
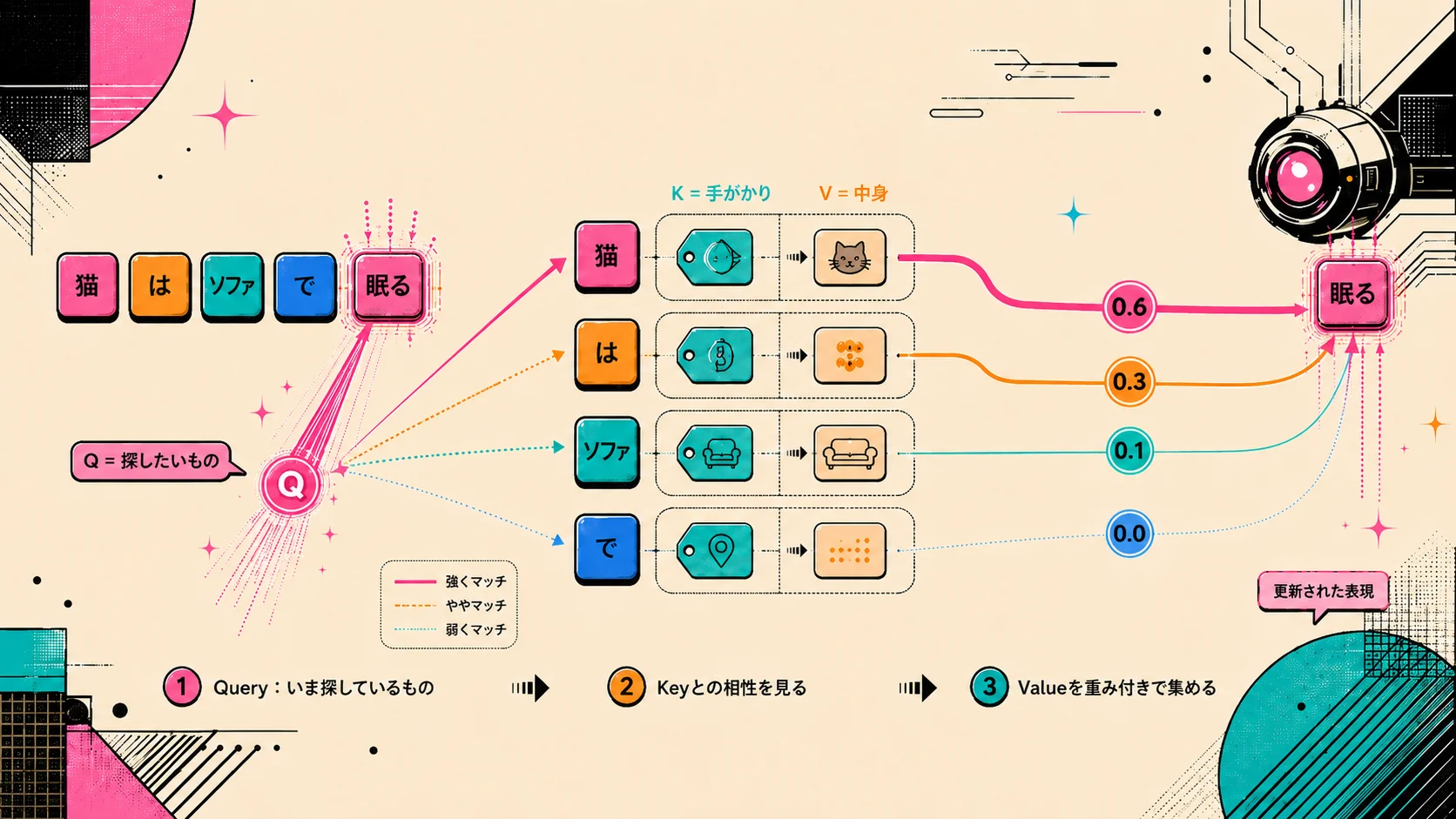
Attentionを読むと、かなり早い段階で Query, Key, Value が出てきます。
Q、K、Vです。
最初はちょっと謎です。
なぜ急にデータベースみたいな言葉が出てくるのか。
なぜ単語に鍵が生えているのか。
Valueとは何なのか。
これは検索の比喩で考えると少しわかりやすくなります。
ざっくり言うと、
- Query:いま探しているもの
- Key:検索に引っかかるための特徴
- Value:実際に取り出される中身
です。
たとえば、図書館で本を探すとします。
自分の頭の中には、
TransformerのAttentionについて知りたい
というQueryがあります。
本棚の本には、それぞれタイトル、タグ、分類番号、著者名などがあります。
これがKeyです。
そして、実際に本を開いたときに得られる本文や情報がValueです。
Attentionでも似たことをします。
各トークンから、Query、Key、Valueという3種類のベクトルを作ります。
そして、
自分のQueryと、相手のKeyがどれくらい合っているか
を計算します。
合っていれば、その相手のValueをたくさん受け取る。
あまり合っていなければ、少しだけ受け取る。
つまり、Attentionとはかなり雑に言えば、
ベクトル空間上の検索と重み付き情報取得
です。
各トークンが、自分のQueryで文中を検索し、他のトークンのValueを重み付きで集めてくる。
これがかなり重要です。
Scaled Dot-Product Attention
論文に出てくるScaled Dot-Product Attentionの式はこうです。
急に圧が出てきました。
でも、やっていることを分解すると、そこまで怖くありません。
まず、 です。
これはQueryとKeyの内積を計算しています。
内積は、ざっくり言えば 「向きがどれくらい似ているか」 を見る計算です。
ベクトル同士が似た方向を向いていれば値が大きくなります。
あまり関係なければ小さくなります。
つまり、 は、
このQueryは、どのKeyと相性がいいか
をまとめて計算している部分です。
次に、 で割っています。
ここで は、Keyベクトルの次元数です。QueryとKeyの内積を取るときの、ベクトルの長さだと思ってよいです。
では、なぜ次元数が出てくるのでしょうか。
内積は、各次元ごとの掛け算を足し合わせる計算です。
たとえばKeyとQueryが64次元なら、64個ぶんの小さな相性スコアを足します。128次元なら、128個ぶん足します。
つまり、次元数が大きくなるほど、内積スコアのばらつきが大きくなります。平均が0に近くても、「たまたま大きい値」が出やすくなる、という感じです。
これは、たくさんの人が一斉に「好き!」「嫌い!」と小声で言っているのを全部足し合わせるようなものです。
人数が少なければ、全体の声量はそこまで大きくなりません。でも人数が増えると、たとえ一人ひとりの声が同じくらいでも、合計の声はどんどん大きくなります。
Attentionの内積もそれに近いです。
各次元は小さな投票のようなものです。次元数が増えると、その投票の合計値が大きくなりやすい。
そして、その大きくなったスコアをそのままsoftmaxに入れると、softmaxが極端になります。
softmaxは、スコアを確率っぽい重みに変換する関数です。
でも入力が大きすぎると、声のデカイやつに乗っ取られて
これしか勝たん!!!!!
他は全部ほぼゼロ!!!!!滅!!!!!
みたいな感じになりやすいです。
勢いが強すぎます。
すると、Attentionの重みが一部のトークンにだけ集中しすぎて、学習が不安定になりやすくなります。
そこで、 で割って、内積スコアの大きさを落ち着かせます。
なぜ ではなく なのかというと、内積の分散は次元数 に比例して大きくなり、その標準的な大きさ、つまり標準偏差はだいたい に比例するからです。
つまり、 で割るのは 、
次元が増えたぶんだけ大きくなりすぎた声量を、ちょうどよい音量に戻す
ための調整です。
「まあまあ、他の子たちのこともよく見てみな。いったん水飲みなよ」という係です。
そのあとに をかけます。
これで、各トークンに対するAttentionの重みができます。
最後に、それを にかけます。
つまり、重みに応じてValueを混ぜます。
まとめると、この式はこういうことをしています。
QueryとKeyの相性を見る
大きくなりすぎないようにスケールする
softmaxで重みにする
その重みでValueを混ぜる
式としては短いですが、中身は 「検索して、重要度を決めて、情報を集める」を綺麗にまとめた式 です。
softmaxは「視線の配分」
softmaxはAttentionの中でかなり大事なヤツです。
softmaxは、複数のスコアを、合計が1になる重みに変換します。
たとえば、あるトークンが他のトークンを見るとき、
- 猫:0.70
- ソファ:0.10
- 眠い:0.15
- それ:0.05
みたいな重みを作るとします。
これは、
自分の注意の70%を「猫」に向ける
10%を「ソファ」に向ける
15%を「眠い」に向ける
5%を「それ」に向ける
という感じです。
Attentionは、視線をひとつに固定するわけではありません。
複数の場所を、重み付きで同時に見ます。
人間も、文章を読むときに似たことをしている気がします。
ある単語を理解するときに、文中のひとつの単語だけを見ているわけではありません。
複数の文脈をぼんやり同時に見ています。
Attentionのsoftmaxは、その視線の配分表のようなものです。
ちなみに私の友人は 田んぼの草刈りのイメージ だと言っていました。
全部を一気に見るのではなく、 どこが伸びているか、どこを刈るべきか、重みをつけて眺める感じ でしょうか。
Multi-Head Attention
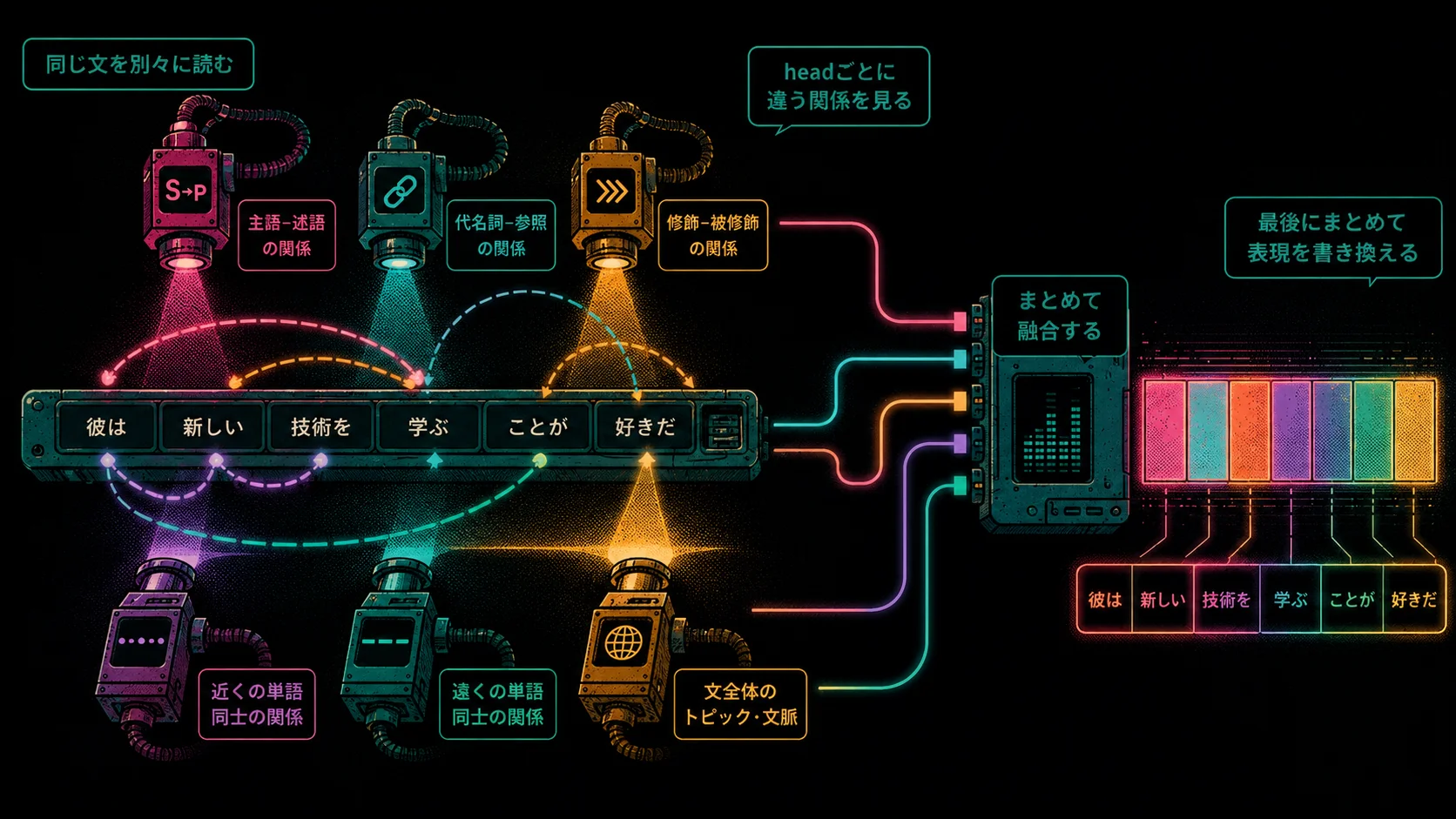
次に出てくる重要概念が Multi-Head Attention です。
これは、 Attentionを複数個並べる仕組み です。
ひとつのAttentionだけでは、ひとつの見方しかできません。
でも文章には、いろいろな関係があります。
たとえば、
- 主語と述語の関係
- 代名詞と参照先の関係
- 修飾語と被修飾語の関係
- 時制や順序の関係
- 意味的に近い語の関係
- 文全体のトピック
などがあります。
これらを、ひとつのAttentionだけで全部うまく見るのは大変です。
そこでTransformerでは、複数のAttention headを用意します。
Multi-Head Attentionの headは 、身近な機械に例えると、 「スキャナの読み取りヘッド」と「プリンタの書き込みヘッド」が一体になったもののような感じ です。
まず、各headは文全体をスキャンします。
ただし、すべてのheadが同じように読むわけではありません。
あるheadは、主語と述語の関係を読み取りやすいかもしれません。
別のheadは、代名詞が何を指しているかを見ているかもしれません。
また別のheadは、近くの単語との関係を重視しているかもしれません。
さらに別のheadは、遠くにある単語とのつながりを見ているかもしれません。
もちろん、実際に「このheadは文法担当です」と人間がきれいに決めているわけではありません。
学習の結果として、それぞれのheadが異なる関係の取り方をするようになる、くらいに考えるのがよさそうです。
ニューラルネットワークには、そういう「よくわからないけど効いているやつ」がいます。
各headは、同じ文章を別々の観点からスキャンします。
そして、読み取った結果をもとに、各トークンの表現を書き換えます。
このトークンは、あのトークンから情報をもらったほうがよさそう
この単語は、文頭の名詞と関係が深そう
この位置の意味は、少し前に出てきた語で補ったほうがよさそう
そういう重みづけをして、Valueを混ぜた結果を、次の層に渡す表現として出力します。
なのでheadは、単なる読者ではありません。
文章をスキャンして、関係を読み取り、その読み取り結果をトークン表現に焼き込む、小さな読み書きヘッドです。
ひとつのheadだけだと、ひとつの読み方しかできません。
でもMulti-Head Attentionでは、複数のheadが同じ文章を別々の観点からスキャンし、それぞれ違う情報の混ぜ方をします。
そして最後に、それらのheadの出力をまとめます。
イメージとしては、ひとつの文章を複数の読み取りヘッドでなぞり、それぞれが見つけた関係性を、次の層の表現に印字していくようなものです。
Transformerは、文章を一度読んで終わりではありません。
各層で何度もスキャンし、何度も関係を読み取り、何度も表現を書き換えます。
その積み重ねによって、最初はただのトークン列だったものが、だんだん文脈を含んだ表現に変わっていきます。
そう考えると、 Multi-Head Attentionは、
文章を複数の観点から同時に読み、その読み取り結果を表現に書き戻す仕組み
だと言えます。
位置情報がない問題
Self-Attentionには大きな問題があります。
そのままだと、順番がわかりません。
Attentionは、トークン同士の関係を見るのは得意です。
でも、入力をただの集合のように扱ってしまうと、
ヤクザがヤンキーを追いかけた
と
ヤンキーがヤクザを追いかけた
の違いがわからなくなります。
これは困ります。
かなり困ります。
ヤクザとヤンキーの勢力図が逆になります。
RNNなら、前から順番に処理するので、順序情報は自然に入ります。
でもTransformerは、順番に処理することをやめたので、別の方法で位置情報を入れる必要があります。
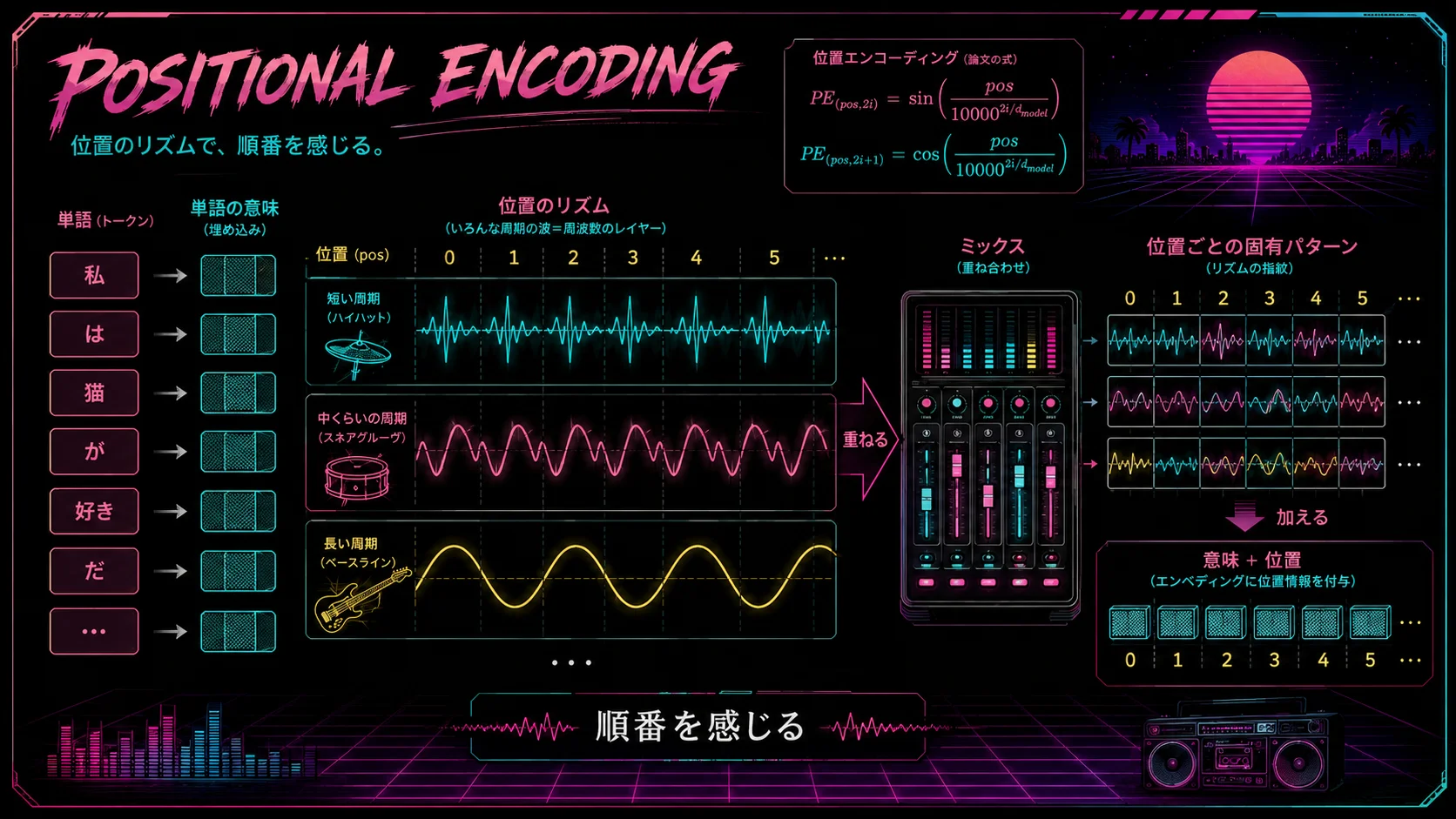
そこで出てくるのが Positional Encoding です。
Transformerでは、各トークンの埋め込みに、位置を表すベクトルを足します。
つまり、
この単語は何か
+
この単語は何番目にあるか
を合わせてモデルに渡します。
論文では、sinとcosを使った固定の位置エンコーディングが使われています。
式はこうです。
急に三角関数が出てきました。
やめてほしい。
でも、気持ちとしては、
位置ごとに、複数の波を組み合わせた固有のリズムをつける
という感じです。
sinとcosは周期のある波です。
短い周期の波もあれば、長い周期の波もあります。
短い周期の波は、近い位置の違いを細かく刻みます。
長い周期の波は、もっと大きなスパンで位置の違いを表します。
音楽で例えるなら、細かく鳴るハイハットのような波もあれば、ゆっくりうねるベースラインのような波もあります。
ハイハットだけだと細かい刻みはわかるけれど、大きな流れは見えにくい。
ベースだけだと大きな流れは見えるけれど、細かい位置の違いはわかりにくい。
そこで、複数の周期の波を重ねます。
細かいリズム。
中くらいのリズム。
ゆっくりしたリズム。
それらを組み合わせることで、それぞれの位置に固有のパターンを与えます。
つまり、ただの番号を足すのではなく、
複数の波でできた位置のリズム音
をトークンに足しているようなものです。
これによって、モデルは「このトークンがどの位置にあるか」を知ることができます。
単語そのものの意味に、位置のリズムを重ねる。
その結果、Transformerは順番に処理しなくても、トークンの並びを扱えるようになります。
EncoderとDecoder
元のTransformerは、Encoder-Decoder構造です。
これは、もともと機械翻訳を主な対象にしていたためです。
どういうことかというと、たとえば、英語を日本語に翻訳するとします。
I love cats.
これを、
私は猫が好きです。
に変換したい。
このときTransformerは、大きく分けて2つの部分に分かれます。
ひとつが Encoder。
もうひとつが Decoder です。
Encoder は、入力文を読む係です。
英語の文を受け取り、それぞれのトークンが文中でどういう意味を持つのかを、Self-Attentionを使って整理します。
つまり、
I
love
cats
という単語列を、そのまま単語の並びとして見るのではなく、
I は love の主語っぽい
love は cats に向かっている
cats は love の対象っぽい
というように、文中の関係を含んだ内部表現に変換します。
Encoderは、入力文全体を見てよいです。
なぜなら、入力文はすでに全部与えられているからです。
翻訳元の英文は、最初から全部読めます。
なのでEncoder側のSelf-Attentionでは、各トークンが入力文全体を見ながら、自分の表現を更新できます。
イメージとしては、Encoderは文章をスキャンして、
この文はこういう構造をしている
この単語とこの単語は関係している
全体としてこういう意味になっている
という、文脈つきの地図を作る係です。
一方で Decoderは、その地図を見ながら、出力文を生成する係です。
Encoderが作った内部表現を参照しながら、
私は
猫が
好きです
のように、日本語の文を1トークンずつ作っていきます。
ここで大事なのは、Decoderは「書き出す側」だということです。
Encoderが読んだ内容をもとに、Decoderが別の言語で文章を書いていく。
つまり、
Encoder:入力文を読んで、「意味の地図」を作る
Decoder:その地図を見ながら、出力文を書いていく
という役割分担です。
機械っぽく例えるなら、Encoderは原稿を読み取るスキャナです。
ただし、ただ画像としてスキャンするのではなく、文中の関係や意味まで読み取って、内部表現に変換します。
Decoderは、その読み取られた内部表現を見ながら、別の言語で印字していくプリンタのようなものです。
読み取り専用の装置と、書き出し用の装置がつながっている感じです。
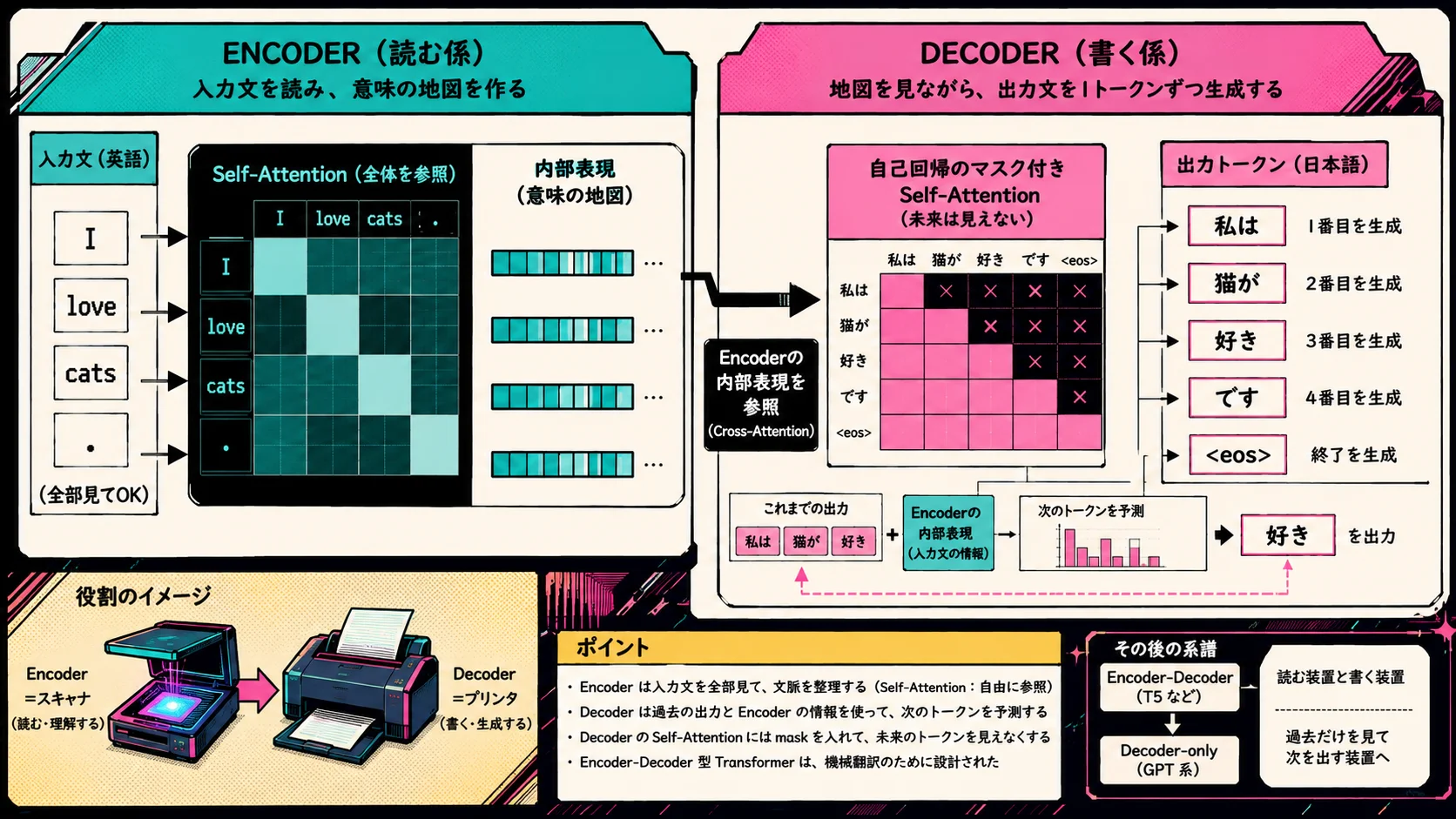
ただし、Decoderには注意が必要です。
Decoderは、出力文を1トークンずつ生成します。
たとえば、
私は猫が
まで生成している時点で、次が「好き」だと知ってはいけません。
未来を見たらカンニングです。
出力文の正解がすでに全部見えている状態で学習するときでも、Decoderには未来のトークンを見せないようにします。そうしないとDecoderは上手いカンニングの仕方だけを覚えたクソガキになってしまうからです。
そのため、Decoder側のSelf-Attentionには mask が入ります。
maskによって、まだ生成していない未来のトークンを見えなくします。
つまりDecoderは、
ここまでに自分が書いた内容
+
Encoderが読んだ入力文の情報
を使って、次のトークンを予測します。
Encoderが翻訳元の文を読む。
Decoderが翻訳先の文を書く。
読む側と書く側が分かれているわけです。
そして、この「未来を見ないようにしながら、ここまでの文脈から次を出す」というDecoder側の仕組みが、GPT系のDecoder-onlyモデルにもつながっていきます。
GPTはざっくり言えば、
ここまでの文脈から、次のトークンを予測する
モデルです。
Encoder-Decoder型のTransformerからEncoder側を外し、Decoder側を巨大化して、次トークン予測に特化させたものとして見ると、かなり理解しやすくなります。
「あれ、Decoderだけにしたら未来を予測して新しい文章を作れるんじゃね?」という発想です。
これが、現在のチャット系LLMが「文章を生成するAI」として見られる大きな理由のひとつです。
もちろん、実際のGPT系モデルは細部がいろいろ違いますが、大きな流れとしては、
元Transformer:入力文を読むEncoder + 出力文を書くDecoder
GPT系:過去文脈だけを見て続きを書くDecoder-only
という整理ができます。
Encoderは、すでにある文章を読むための装置。
Decoderは、まだない文章を少しずつ書いていくための装置。
この違いを押さえておくと、BERT系、T5系(Encoder-Decoder)、GPT系(Decoder-only)の違いが見えやすくなります。
特に、現在よく話題になるチャット系・生成系LLMはDecoder-onlyであることが多いです。
※ 厳密には、元論文のDecoderにはEncoder出力を見るCross-Attentionがあります。GPT系のDecoder-onlyモデルでは基本的にそれを持たず、未来を見ないSelf-Attentionを積み重ねます。
Feed Forward Networkとかいうヤツもいる
TransformerというとAttentionばかり注目されます。
タイトルも Attention Is All You Need です。
でも、実際にはAttentionだけで全部ができているわけではありません。
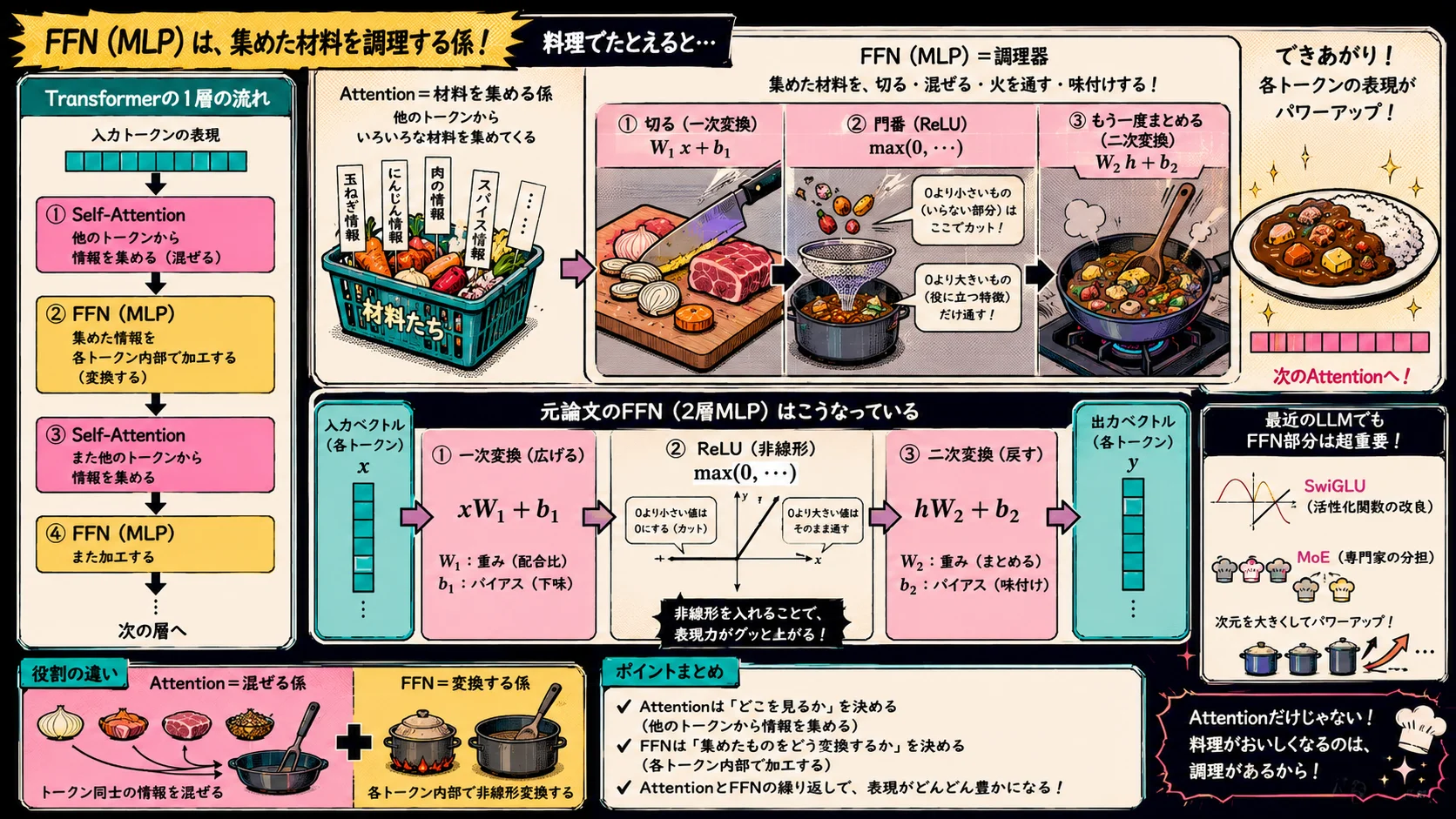
各層には、Position-wise Feed Forward Network、つまりFFNも入っています。
中の仕組みに MLP、Multi-Layer Perceptronを使うことが多いので、MLP層と呼ばれることもあります。
……急にMLPと言われても困ります。
私もよくわからなくて「あーね」となったことがあります。
MLPは、ものすごくざっくり言えば、普通のニューラルネットワークです。
入力を受け取る。
重みをかける。
バイアスを足す。
活性化関数を通す。
また重みをかける。
そうやって、入力されたベクトルを別のベクトルに変換します。
料理で言えば、Attentionが外から材料を集めてくる係だとすると、MLPはその材料を切ったり混ぜたり火を通したりする調理器です。
材料を集めただけでは料理になりません。
玉ねぎ、にんじん、肉、スパイスを集めても、そのまま皿に乗せたらだいぶワイルドです。
そこでMLPが、それらを加工します。
TransformerのFFNも、だいたいそういう役割です。
Attentionが、
他のトークンから情報を集める係
だとすると、Feed Forward Networkは、
集めた情報を各トークン内部で加工する係
です。
Attentionで周囲を見る。
FFNで自分の中で考える。
またAttentionで周囲を見る。
またFFNで加工する。
この繰り返しです。
人間っぽく言うと、
周りの話を聞く
自分の中で咀嚼する
また周りを見る
また考える
という感じかもしれません。
元論文のFFNは、かなり素直な2層MLPです。
急に式が出てきました。
でも、やっていることはそこまで複雑ではありません。
まず、 で入力ベクトルを一度変換します。
は重みです。
はバイアスです。
重みは、入力のどの成分をどれくらい使うかを決める係です。
バイアスは、全体を少しずらす係、オフセットです。
たとえるなら、重みはミキサーの配合比、バイアスは味の下味みたいなものです。
そのあとに が出てきます。
これが ReLU です。
ReLUは、Rectified Linear Unitの略です。
名前はこわいですが、やっていることはとても単純です。
0より大きい値はそのまま通す
0より小さい値は0にする
という関数です。
つまり、
です。
マイナスの値を切り捨てて、プラスの値だけを通す。
門番みたいなものです。
プラスの人は通ってよし
マイナスの人はここで止まってください
という感じです。
なぜこんなものを挟むのかというと、これによってニューラルネットワークが単なる線形変換の積み重ねではなくなるからです。
重みをかけるだけの処理を何回重ねても、結局は大きな1回の線形変換にまとめられてしまいます。
それだと表現力が足りません。
途中にReLUのような非線形な関数を挟むことで、
ある特徴が出ているときだけ通す
ある方向の情報は消す
入力によって処理のされ方を変える
ことができるようになります。
料理の比喩で言うなら、ただ混ぜるだけではなく、
焦げた部分は捨てる
火が通ったものだけ次へ進める
一定以上の味が出たものだけ採用する
みたいな工程です。
そして最後に、 と によるもう一度の線形変換で、広げた次元を元の形に戻します。
つまり元論文のFFNは、
一度広げる
ReLUで不要なものを切る
もう一度戻す
という構造です。
ReLUを挟んで、次元を広げて、また戻す。
シンプルです。
ここで大事なのは、FFNは基本的に各トークンごとに独立に適用されるということです。
トークン同士を混ぜるのはAttentionです。
各トークン内部で非線形変換するのがFFNです。
つまり、
Attentionは混ぜる
FFNは変換する
という役割分担があります。
この視点は、最近のLLMを読むときにもかなり重要です。
なぜなら、最近のモデルでもFFN部分は巨大で、しかもSwiGLUやMoEのような改造の中心になりやすいからです。
Attentionだけ見ていると、Transformerの理解は少し偏ります。
Attentionは「どこを見るか」を決める。
FFNは「見て集めたものをどう変換するか」を決める。
この両方があって、Transformerは動いています。
ちなみに、少し面白い豆知識があります。
LLMの知識は、AttentionよりもMLP、つまりFFN側に多く保持されているらしい
LLMの知識は、AttentionよりもMLP、つまりFFN側に多く保持されていることがあるらしいです。
もちろん、これは「Attentionには知識がない」という意味ではありません。
Attentionは、文脈の中でどこを見るかを決めたり、必要な情報を別の位置から運んできたりするのが得意です。
一方でMLPは、各トークンの表現を内部で変換します。
このとき、モデルが学習した事実関係や特徴が、MLPの重みの中にかなり蓄えられていると見る研究があります。
たとえば、
パリはフランスの首都である
Eiffel Tower は Paris にある
ある人物の職業や出生地は何か
のような factual knowledge、つまり事実関係っぽい知識は、Attentionそのものというより、MLP層の変換として出てくることが多いようです。
かなり雑に言うと、
Attentionは情報を探して運ぶ係
MLPは内部に持っている知識や特徴を呼び出して変換する係
という見方ができます。
TransformerのFFNを「各トークンごとの加工係」と説明しましたが、実際にはこの加工係がかなり物知りだった、という感じです。
モデル解析の研究では、BERT系のFFNがkey-value memoryのように働くという話があります。
また、GPT-JやGPT-NeoXのようなモデルでは、特定の事実を編集するときに、中間層のMLPを変えるとモデルの出力が大きく変わる、という研究もあります。
つまり、モデルによって偏りはありますが、
Attentionは文脈の中で「どこを見るか」を決める
MLPはそのトークン表現に「何を思い出させるか」を強く担う
という整理は、最近のTransformer理解ではかなり重要です。
これは、最近のLLMでFFN部分が巨大だったり、SwiGLUで強化されたり、MoEでExpert化されたりする理由を考えるうえでも面白いです。
Attentionだけが賢いのではありません。
むしろ、知識を抱え込んでいるのは、案外この地味なMLP側かもしれません。
Attentionが図書館の中でどの本を見るかを決める司書だとすると、MLPは、その本を読んだあとに頭の中で意味を展開する物知りな調理器です。
調理器が物知り。
だいぶ変ですが、Transformerではそういうことが起きているのかもしれません。
残差接続とLayerNorm
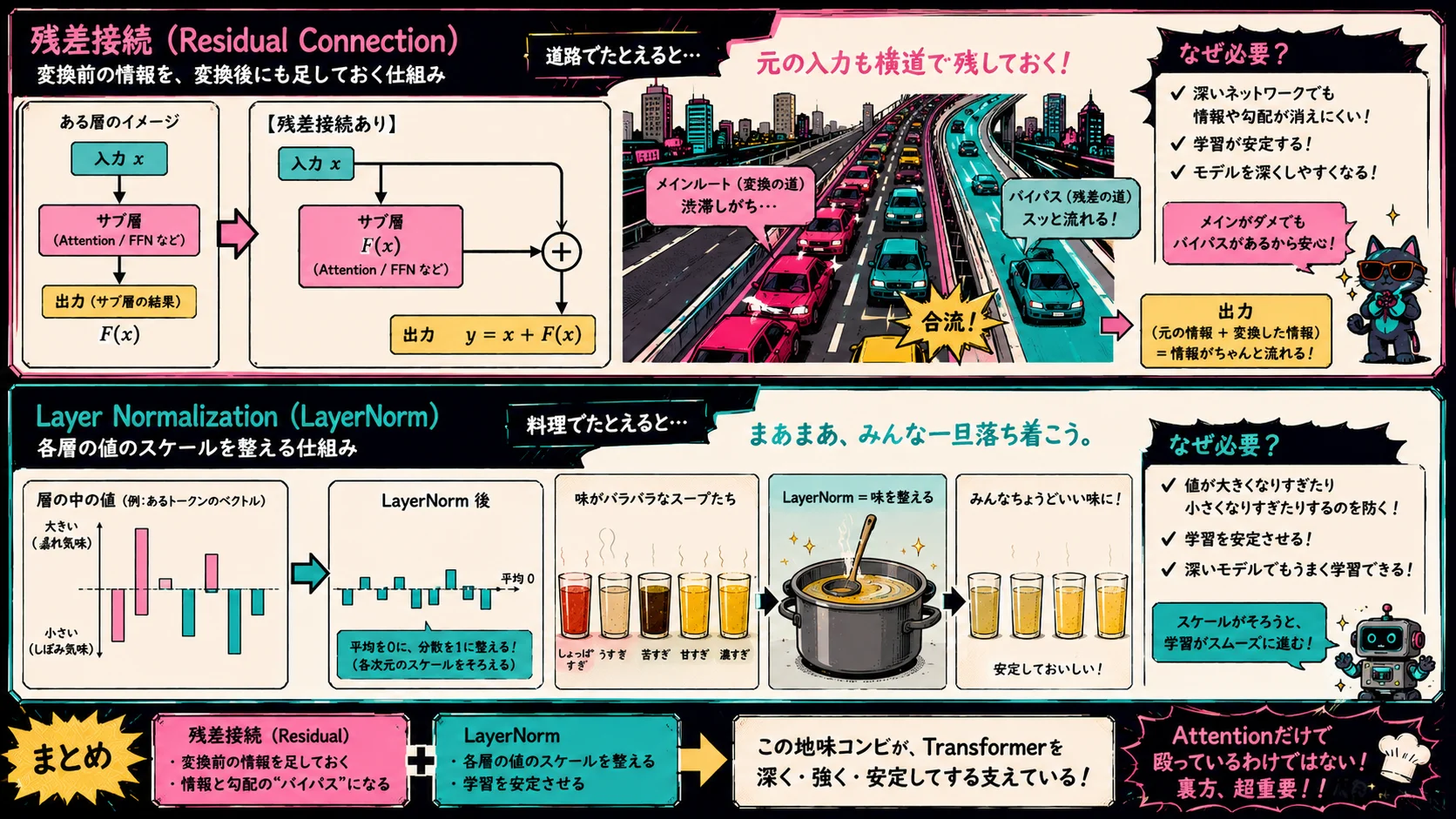
論文のTransformerには、残差接続とLayer Normalizationも入っています。
残差接続
残差接続は、ざっくり言えば、変換前の情報を、変換後にも足しておく仕組みです。
ニューラルネットワークを深くすると、情報や勾配が途中で消えたり、学習が不安定になったりします。
そこで、元の入力も横道で残しておくようにします。
道路で言えば、メインルートが渋滞してもバイパスがある感じです。
LayerNorm
LayerNormは、各層の値のスケールを整える仕組みです。
ニューラルネットワークの中では、値が大きくなりすぎたり小さくなりすぎたりすると学習が不安定になります。
LayerNormはそれを整えて、
まあまあ、みんな一旦落ち着こうや
という状態にします。
Transformerは派手なAttentionが主役に見えますが、こういう地味な安定化機構もかなり大事です。
Attentionだけで殴っているわけではありません。
裏方がちゃんといます。いつもありがとね。
ただ、LayerNormはパラメータ数としては小さいですが、実行時には意外と面倒な処理です。
各トークンのベクトル全体を見て、平均や分散を計算し、その結果を使って全要素を正規化する必要があります。
つまり、ただ行列を掛けるだけではなく、一度全体を集計してから各要素を書き換える処理になります。
GPUは巨大な行列積は得意ですが、こういう集計とメモリアクセスの多い処理は苦手です。
そのため、最近のLLMではLayerNormをRMSNormのような軽めの正規化に置き換えたり、Normの置き方を工夫したりすることが多くなっています。
計算量の話
Self-Attentionには弱点もあります。
それは、系列長に対して計算量が大きくなりやすいことです。
Self-Attentionでは、基本的に各トークンが他の全トークンを見るので、トークン数を とすると、関係を見る組み合わせはだいたい になります。
100トークンなら1万。
1000トークンなら100万。
10000トークンなら1億。
急に重い。
全員が全員を見る会議は、人数が増えると破綻します。
10人ならなんとかなる。
100人だと大変。
10000人だと、もはや会議ではなく祭りです。
この問題は、現在のLLMでもかなり重要です。
長いコンテキストを扱うために、FlashAttention、Sparse Attention、Linear Attention、Sliding Window Attention、RoPEの長文拡張など、いろいろな工夫が出てきました。
Transformerは強いですが、万能ではありません。
特に「全トークン同士を見る」という性質は、表現力の強さと計算コストの重さがセットになっています。
現在は、このあたりの計算量やメモリ効率を改善する研究も多いです。FlashAttention 2のような実装最適化や、線形Attention系・状態空間系のように長文処理の構造そのものを見直す方向もあります。
O記法ってよく聞くけどアレなによ?
ここでよく出てくるのが、O記法です。
たとえば、Self-Attentionの計算量はよく、
と書かれます。
これは、厳密な計算回数そのものというより、
入力の長さ が増えたとき、計算量がどんな増え方をするか
を見るための書き方です。
なら、入力が2倍になると計算量もだいたい2倍です。
100トークンが200トークンになったら、処理もざっくり2倍。
わかりやすいです。
一方で、 だと、入力が2倍になると計算量はだいたい4倍になります。
100トークンが200トークンになると、見るべき関係は、
から、
になります。
2倍ではなく4倍です。4倍だぞ4倍。
1000トークンが2000トークンになれば、100万から400万。
増え方がだいぶ暴れます。
先程も出した例えですが、Self-Attentionは、全員が全員を見る会議です。
10人なら、まあ話せます。
100人だと大変です。
10000人だと、もはや会議ではなく祭りです。
GPU上でずっとコミケやってるようなもんです。
この「全員が全員を見る」構造が、 の重さです。
なので、長い文章や長いコンテキストを扱おうとすると、Self-Attentionはかなり重くなります。
ここで、最近よく出てくるのが Linear Attention や、状態空間モデル、Gated Delta Netのような方向です。
これらはかなり雑に言うと、
全員が全員を直接見るのではなく、もっと効率よく情報を流せないか
という発想です。
理想的には、系列長に対して計算量を
に近づけたい。
つまり、入力が2倍になったら、計算量もだいたい2倍で済むようにしたい。
全員が全員と握手するのではなく、伝言板や回覧板や状態ベクトルのようなものを使って、情報を順番に受け渡していくイメージです。
ただし、 にすれば全部解決、というわけでもありません。
Self-Attentionの強さは、任意のトークン同士が直接関係を持てるところにあります。
遠く離れた単語でも、一発で見に行ける。
この直接性をどれくらい保ったまま、計算量を軽くできるか。
そこが最近の長文処理・高速化アーキテクチャの大きなテーマになっています。
ここまでが、元論文としてのTransformerの基本形です。ここから先は少し視点を進めて、「この部品たちが、現在のLLMではどう置き換えられているのか」を見ていきます。
最近のLLMを読むための前段として
ここまで見てきたTransformerは、2017年の元論文に出てくるTransformerです。
ただし、現在のLLMがそのままこの形で動いているかというと、そうではありません。
Attention Is All You Need のTransformerは、今のLLMの原型ではあります。
でも、現在のモデルではかなり多くの部品が置き換えられたり、改良されたりしています。
なので、この論文を読むときは、「これが現在のLLMそのものです」というより、
「ここから現在のLLMアーキテクチャが枝分かれしていった」
と見るのがよさそうです。
Transformerを読むことは、現代LLMを読むための地図の凡例を覚えることに近いと思います。
Attention、FFN、位置エンコーディング、残差接続、LayerNorm。
これらの部品が何をしているのかがわかると、最近のモデルの論文やconfigを見たときに、
あ、これはTransformerのこの部品を置き換えているんだな
と読めるようになります。
ここでは、最近のLLMにつながる代表的な変更点を、軽く整理しておきます。
Positional EncodingからRoPEへ
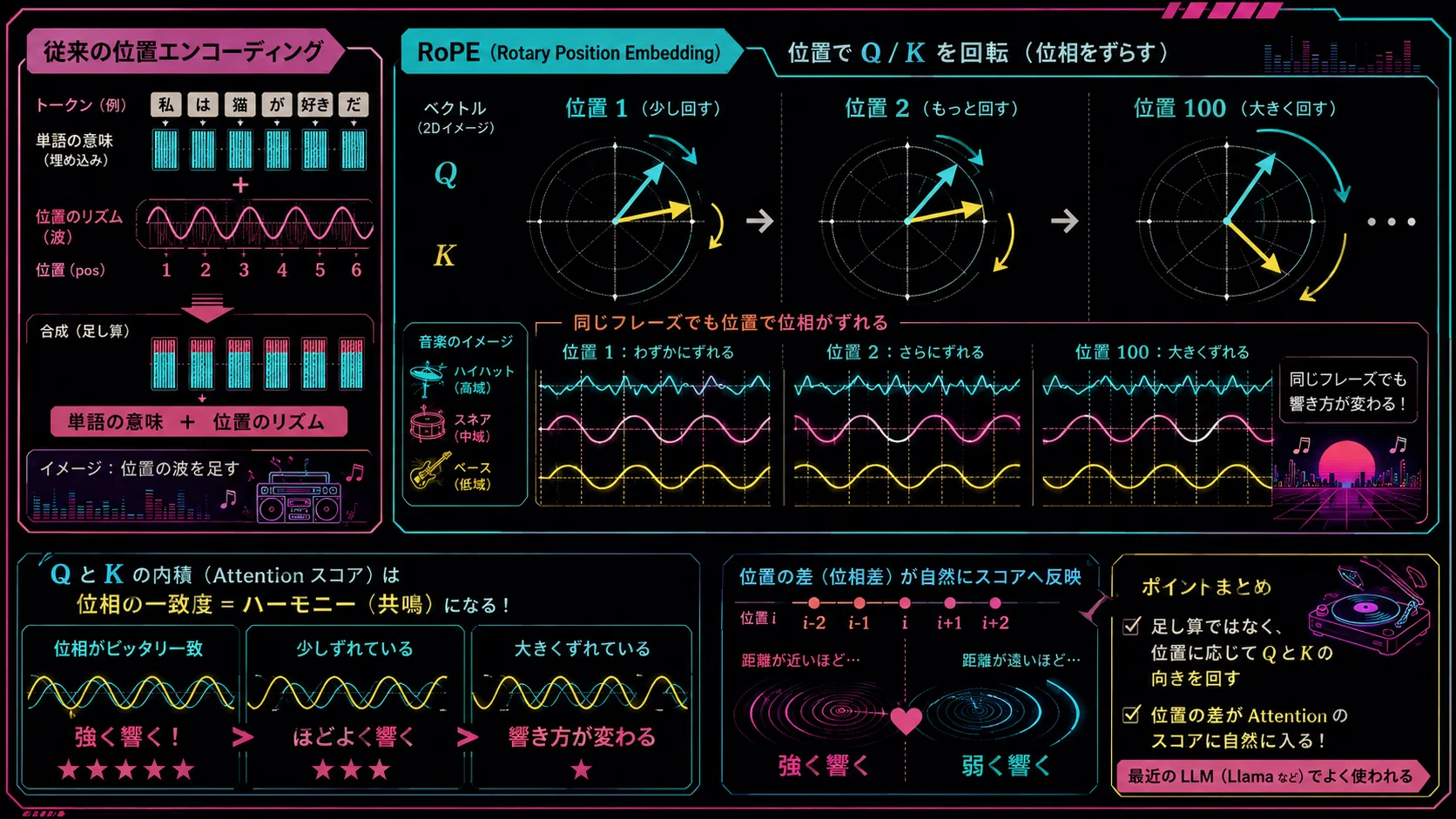
元のTransformerでは、sinとcosを使った固定の Positional Encoding が使われていました。
これは、各トークンに「自分が何番目にいるか」という位置情報を足すための仕組みです。
音楽で例えるなら、単語そのものの音に対して、
この位置ではこういうリズムが鳴っています
という位置専用のリズムトラックを重ねるようなものです。
単語の意味というメロディに、位置を表すビートを足す。
これが、元のPositional Encodingのざっくりしたイメージです。
ただ、最近のLLMでは、元論文のPositional Encodingをそのまま使うことは少なくなっています。
よく使われるようになったのが RoPE、Rotary Position Embeddingです。
RoPEは、かなり雑に言うと、位置情報を、ベクトルの回転としてAttentionに埋め込む仕組みです。
普通の位置エンコーディングは、トークンの埋め込みに「位置を表すベクトル」を足します。
一方でRoPEは、QueryやKeyのベクトルを、位置に応じて回転させます。
たとえば、1番目のトークンは少し回す。
2番目のトークンはもう少し回す。
100番目のトークンはさらに回す。
ここで音楽の比喩に戻ると、RoPEは「位置のリズム音を足す」というより、
位置に応じて、音の位相を少しずつずらす
感じです。
sin波やcos波には、位相があります。
同じ波でも、少し早く始まるのか、少し遅れて始まるのかで、重なり方が変わります。
ドラムのハイハットがほんの少し前ノリになる。
ベースラインが少し後ろにずれる。
同じフレーズなのに、位相が変わることで、他の音との噛み合い方が変わる。
RoPEは、それに近いことをQueryとKeyに対して行います。
QueryとKeyは、Attentionの中で「このトークンとこのトークンはどれくらい合うか」を見るためのベクトルです。
そのQueryとKeyを、位置に応じて回転させる。
すると、内積を取ったときに、単語同士の意味的な相性だけでなく、この2つのトークンは、どれくらい離れた位置にあるのかも自然にわかるようになります。
ここがRoPEの面白いところで、単に「私は何番目です」という名札を貼るというより、位置によって、視線の向きそのものが少し回転するという感じです。
あるいは音楽で言えば、
位置によって、各トークンのフレーズの位相がずれていき、他のトークンとのハモり方が変わる
という感じかもしれません。
同じ音でも、位相が合っていれば強く響き合う。
位相がずれていれば、響き方が変わる。
RoPEでは、位置の差がこの 「響き方の違い」としてAttentionのスコアに入ってきます 。
Attentionでは、QueryとKeyの相性を内積で見ます。
そのQueryとKey自体を位置に応じて回転させることで、
このトークン同士は、どれくらい離れているのか
がAttentionのスコアに自然に入ってきます。
美しいですね。
文章を読むとき、単語の意味だけでなく、
「どれくらい前に出てきた単語なのか」
「近くにあるのか、遠くにあるのか」
も大事です。
RoPEは、その距離感をAttentionの中にかなりきれいに入れる方法だと思います。
元のPositional Encodingが、
位置のリズムをトークンに足す
方法だとすると、RoPEは、
位置によってQueryとKeyの位相を回し、トークン同士の響き方を変える
方法です。
最近のLLMでは、LLaMA系をはじめとして、RoPEやその派生が広く使われています。
なので、元論文のPositional Encodingを読んだあとにRoPEを見ると、位置情報をどう入れるかという問題が、現在のLLMでもかなり重要なテーマであり続けていることがわかります。
FFNからSwiGLUへ
最近のLLMでは、元論文のような素朴なReLU FFNではなく、SwiGLUやGated MLPが使われることが多いみたいです。
GLUはGated Linear Unitの略です。
ざっくり言うと、
値を変換する経路
その値をどれくらい通すか決めるゲート
を持つ構造です。
普通のFFNが「材料を全部ミキサーにかける」 感じだとすると、Gated MLPは、
この材料は通す
これは少し抑える
これはいっぱい入れる
という弁を持っている感じです。
SwiGLUは、そのゲート側にSwish系の活性化を使うGLUです。
かなり雑に書くと、SwiGLUはこういう形をしています。実装や論文によって細部の書き方は少し違いますが、ここでは「ゲートで値を通す」という気持ちを見るための式です。
ここで は要素ごとの掛け算です。
が値の経路。
がゲートの経路。
それを掛け合わせて、最後に で戻します。
要するに、変換した情報に対して、別の経路で作ったゲートをかけるということをしています。
Attentionが文脈から材料を集めてきて、
FFNがそれを料理する。
SwiGLUは、その料理のときに火加減や投入量を調整できるようにしたもの、くらいに見るとよさそうです。
最近のLLMのパラメータ数を見ると、実はFFN部分がかなり大きな割合を占めています。
なので、FFNは地味な付属品ではありません。
Attentionが有名すぎるだけで、FFNも大切な子なのです。愛してるよ。
Decoder-onlyという現在の主流
元のTransformerは、Encoder-Decoder構造でした。
これは機械翻訳を想定していたからです。
Encoderが入力文を読み、Decoderが出力文を生成する。
英語を読んで、日本語を出す。
ドイツ語を読んで、英語を出す。
そういうタスクには自然です。
でも、GPT系のLLMでは主に Decoder-only Transformer が使われます。
Decoder-onlyとは、ざっくり言えば、
Encoderを持たず、Decoder側の仕組みだけで次のトークンを予測するモデル
です。
やっていることはシンプルです。
ここまでのテキストを読む。
次のトークンを予測する。
また次のトークンを予測する。
これを繰り返します。
つまり、
文脈 → 次トークン
文脈 + 次トークン → さらに次トークン
という形で文章を伸ばしていきます。
このとき重要なのが、未来を見ないmaskです。
Decoder-onlyモデルは、学習時にも未来のトークンを見ないようにして、過去の文脈だけから次を予測します。
これは一見かなり単純です。
でも、大量のテキストでこの次トークン予測を学習すると、翻訳、要約、質問応答、コード生成、対話など、何故かかなり多くの能力が出てきます。
不思議です。
次の単語を当てていただけのはずなのに、いつの間にか教えてないはずのことができるようになる。
ここがLLMのかなり面白いところです。
元論文のTransformerを読んだあとにGPT系を見ると、
あ、Encoder-Decoderのうち、Decoder側を巨大化して、次トークン予測に特化させたんだね
という見方ができます。
もちろん細部は違いますが、だいたいそんな感じです。
LayerNormからRMSNormへ
元論文のTransformerでは、Layer Normalizationが使われています。
LayerNormは、各層の値のスケールを整える仕組みです。
ニューラルネットワークは、層を深くすると値の分布が暴れやすくなります。
大きくなりすぎたり、小さくなりすぎたり、勾配が不安定になったりします。
テンションの高い陽キャが多いとうるさいし、テンションの低い陰キャが多いと静まりかえってしまうような感じです。
LayerNormは、それを整えて、
まあまあ、みんな一旦同じくらいのテンションでいこう
という状態にします。
最近のLLMでは、LayerNormの代わりに RMSNorm が使われることも多いです。
RMSNormは、LayerNormより少し簡略化された正規化です。
平均を引く処理を省き、二乗平均平方根、つまりRMSでスケールを整えます。
ざっくり言えば、
中心を揃えるというより、ノルム(ベクトルの長さ)の大きさを揃える
感じです。
計算が少し軽くなり、実装上も扱いやすい場合があります。
LLaMA系などでもRMSNormが使われています。
このあたりは細かい部品に見えますが、巨大モデルではかなり効きます。
LLMは巨大なビルのようなものなので、
ひとつひとつの階層を安定して積むための部品がとても大事になります。
AttentionやFFNが目立つ鉄骨だとすると、
Normは水平を取るための小さな調整具みたいなものかもしれません。
地味ですが、ないとビルが傾きます。
Pre-Normという積み方
TransformerのNormまわりでは、もうひとつ Pre-Norm という話もあります。
元論文のTransformerでは、ざっくり言うと、サブレイヤーのあとにLayerNormを置く構成でした。
一方で、最近の深いTransformerでは、サブレイヤーに入る前にNormを置くPre-Norm構成がよく使われます。
かなり単純化すると、
Post-Norm:処理してから整える
Pre-Norm:整えてから処理する
という違いです。
深いモデルでは、Pre-Normのほうが学習が安定しやすいことがあります。
これは、ものすごく感覚的に言うと、
荒れた入力をいきなり層に突っ込むのではなく、
まず姿勢を整えてから作業に入る
感じです。
Transformerを何十層、何百層と積むと、こういう安定性の差がかなり大きくなります。
最近のLLMを読むと、AttentionやFFNだけでなく、Normをどこに置くかも重要な設計要素として出てきます。
地味です。
でも、巨大なモデルでは地味な安定性がかなり大事です。
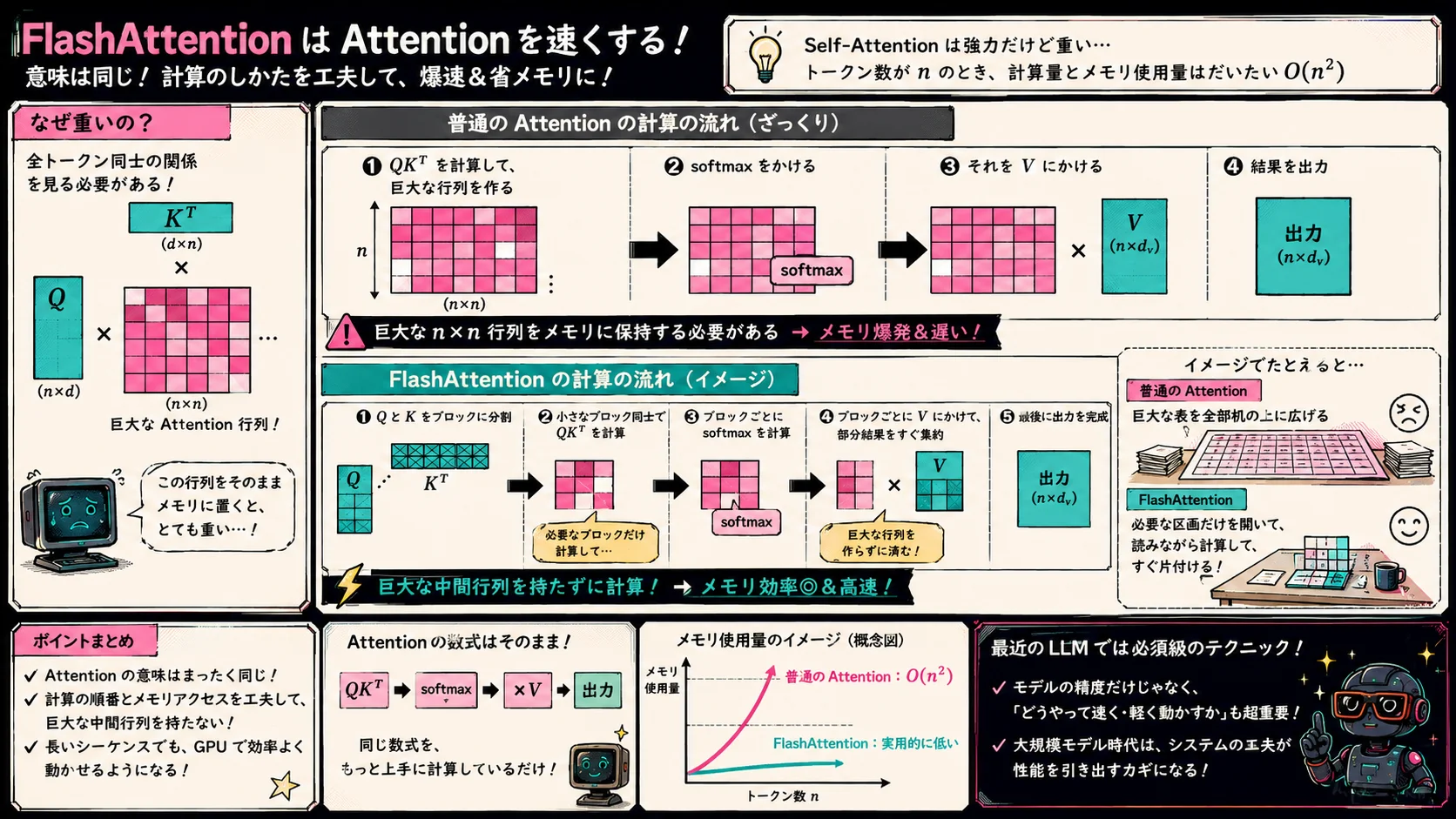
FlashAttentionはAttentionを速くする
Self-Attentionは強力ですが、計算量とメモリ使用量が重いです。
トークン数が増えると、全トークン同士の関係を見る必要があるため、だいたい で重くなります。
この問題に対して、最近のLLMでは FlashAttention のような高速化手法がよく使われます。
FlashAttentionは、Attentionの数式そのものを変えるというより、
同じAttentionを、GPU上でメモリ効率よく計算する
ための方法です。
Attentionでは、 によって大きなAttention行列を作ります。
でも、この行列をそのままメモリに置くと、とても重い。
FlashAttentionは、計算の順番やメモリアクセスを工夫して、巨大な中間行列をできるだけ持たずにAttentionを計算します。
イメージとしては、巨大な表を全部机の上に広げるのではなく、
必要な区画だけを開いて、読みながら計算して、すぐ片付ける感じです。
Attentionの意味は同じです。
でも、実装がイカしています。
この「意味は同じだけど、計算の仕方を変える」というのも、最近のLLMを読むときにはかなり大事です。
論文やモデル説明を読んでいると、アーキテクチャの発明だけでなく、
どうすれば巨大なモデルを現実のGPUで動かせるか
という工夫がたくさん出てきます。
LLMは数学だけでなく、システムの話でもあります。
MoEはFFNをたくさん持つ
最近の大規模モデルでは、MoE、Mixture of Expertsという構造もよく出てきます。
MoEは、ざっくり言うと、
たくさんの専門家ネットワークを用意して、入力ごとに一部だけ使う
仕組みです。
TransformerにおけるMoEは、多くの場合、FFN部分を複数のExpertに分けます。
普通のDense Transformerでは、すべてのトークンが同じFFNを通ります。
Denseというのは、ざっくり言えば、
モデルの中身を毎回ぜんぶ使う構造
です。
すべてのトークンが、同じAttention層と同じFFN層を通ります。
一方でMoEでは、複数のFFN、つまりExpertが用意されています。
そして、ルーターが、
このトークンはExpert 3とExpert 12に投げよう
のように、使うExpertを選びます。
これによって、モデル全体のパラメータ数は大きくできます。
でも、1回の推論で使うパラメータは一部だけにできます。
つまり、図書館全体は巨大だけど、毎回読む本は数冊だけという感じです。
これはかなりスケーリングに効きます。貴重な計算資源をケチれるわけです。
モデルにたくさんの知識や変換能力を持たせたい。
でも毎回全部を使うと重すぎる。
だから、必要そうなExpertだけを呼ぶ。
MoEは、そういう発想です。
最近の例だと、DeepSeek-V3やDeepSeek-R1のようなモデルは、MoEのわかりやすい成功例として見ることができます。分散学習・分散推論の文脈では、よわよわGPUでもたくさん集まればマグロをしばけるのです。LLM界のスイミーです。
総パラメータ数は非常に大きい。
でも、推論時に毎回使うパラメータはその一部だけ。
そのため、Denseモデルと比べて、巨大な容量を持ちながら、実際の計算量を抑えることができます。
また、Expertごとに計算を分けられるので、分散処理とも相性がいいです。
巨大なDenseモデルでは、毎回モデル全体を通る必要があります。
一方でMoEでは、入力ごとに使うExpertを選び、一部のExpertだけを動かします。
イメージとしては、 Denseモデルが「全社員参加の会議」 だとすると、 MoEは「案件ごとに専門部署を呼ぶ会議」 です。
全社員が毎回出ると、情報共有は安定します。
でも重いですし、処理にも時間がかかります。
専門部署だけを呼ぶと、速く、効率よく処理できます。
でも、誰を呼ぶかを間違えると困ります。
ここがMoEの難しさです。
Denseモデルにも強みがあります。
Denseモデルは、すべてのトークンが毎回同じパラメータ全体を通るため、モデル全体が一体として働きます。
そのため、挙動が比較的安定しやすく、ルーティングの失敗もありません。
すべての層、すべての重みが、毎回ちゃんと関与します。
これは、長い文脈で一貫した処理をしたい場合や、ルーティングに左右されない安定性が欲しい場合には有利です。
MoEは、必要なExpertだけを呼ぶことで効率よく巨大化できます。
Denseは、全体を毎回使うことで、密度の高い一体的な処理をしやすい。
かなり雑に言うと、
MoEは、巨大な専門家集団を必要に応じて呼ぶモデル
Denseは、ひとつの大きな脳全体で毎回考えるモデル
です。

もちろん、「MoEは浅い」「Denseは必ず深い」と単純に決まるわけではありません。
MoEでも非常に強い推論モデルはあります。
DeepSeek-R1のように、MoE構造でも推論能力の高いモデルは出てきています。
逆にDenseでも、サイズや学習が足りなければ強い推論はできません。
なので、これは絶対的な優劣ではなく、設計思想の違いとして見るのがよさそうです。
MoEの得意なところは、
- 総パラメータ数を大きくしやすい
- 推論時に使う計算量を抑えやすい
- Expertごとに分散処理しやすい
- 知識や能力を専門家のように分けて持たせやすい
一方で、MoEには難しさもあります。
- ルーターがうまくExpertを選ぶ必要がある
- 一部のExpertだけが使われすぎると負荷が偏る
- Expert間の通信や分散処理が複雑になる
- 学習も実装もDenseモデルより難しくなりやすい
Denseモデルの得意なところは、
- 構造がシンプル
- ルーティングの失敗がない
- 全パラメータが毎回関与する
- 挙動が一体的で安定しやすい
あたり。
つまり、
MoEはスケールと効率のための構造
Denseは一体性と安定性のための構造
と見るとわかりやすいです。
元Transformerと最近のLLMの対応表
ここまでの話を雑に表にすると、こんな感じです。
| 元Transformerの部品 | 最近のLLMでよく見る変化 | ざっくり何が変わったか |
|---|---|---|
| Sinusoidal Positional Encoding | RoPE, ALiBiなど | 位置情報の入れ方が変わった |
| ReLU FFN | SwiGLU, Gated MLP | FFNにゲートが入った |
| Encoder-Decoder | Decoder-only | 次トークン予測に特化した |
| LayerNorm | RMSNorm, Pre-Norm構成 | 深いモデルを安定にした |
| 通常Attention | FlashAttention | 意味は同じまま高速・省メモリ化した |
| Dense FFN | MoE | FFNを専門家に分け、一部だけ使う |
| 絶対位置寄りの扱い | 相対位置・長文拡張 | 長い文脈を扱いやすくした |
こうして見ると、現代LLMはTransformerを捨てたわけではありません。
むしろ、Transformerの各部品を、
もっと深くする
もっと速くする
もっと長くする
もっと安定させる
もっとスケールさせる
方向に改造してきたものだと見えます。
元論文を読む意味は、ここにあります。
今のモデルだけを見ると、RoPE、RMSNorm、SwiGLU、MoE、FlashAttentionなど、知らない部品が一気に出てきて混乱します。
でも、元のTransformerの構造を知っていると、
あ、この部品の後継なんだな
ここを置き換えているんだな
ここを高速化しているんだな
と読めるようになります。
Transformerは、現代LLMの完成形ではありません。
でも、現代LLMを読むための骨格です。
骨格が見えると、そこに後から付いた筋肉や補助具も見えやすくなります。
この論文がLLMにつながったところ
Attention Is All You Needは、もともとは機械翻訳の論文です。
今のようなチャットAIを直接作るための論文ではありません。
でも、この論文が示したことは、その後のLLMにとってかなり重要でした。
特に大事なのは、
並列化しやすく、スケールしやすい系列モデル
を作ったことです。
RNNのように順番に処理する構造だと、大規模化するときに限界が出やすい。
Transformerは、Attentionによって文脈内の関係を扱いながら、GPUで効率よく学習しやすい構造を持っていました。
そして、モデルを大きくする。
データを増やす。
計算量を増やす。
すると、言語モデルの性能がかなり伸びることがわかってきます。
もちろん、現在のLLMには元論文から多くの変更があります。
たとえば、
- GPT系ではDecoder-only Transformerが使われる
- 位置情報にはRoPEなどが使われることが多い
- 活性化関数やFFN構造も改良されている
- Attention計算もFlashAttentionなどで高速化されている
- MoEのような構造も使われる
など、今のモデルはかなり進化しています。
それでも、中心にある発想はかなりTransformerです。
文脈中のトークン同士の関係を見る。
その関係を層ごとに更新する。
次のトークンを予測する。
その巨大な積み重ねが、今のLLMのかなり大きな部分を作っています。
読んでいて面白かったところ
個人的に面白いのは、Transformerが文章を「時間」ではなく「場」として扱っているように見えるところです。
RNNは、文章を時間的な流れとして読む感じがあります。
前から後ろへ。
過去の状態を持って、次へ進む。
一方でSelf-Attentionは、文章の中の各トークンが互いに関係を持つ空間を作ります。
もちろん、位置情報はあります。
未来を見ないmaskもあります。
だから完全に順序を捨てているわけではありません。
でも、中心にあるのは、
次の状態へ流れる
というより、
関係の網を張る
という感じです。
文章は、単語が一列に並んだものです。
でも意味は、単純な一列ではありません。
ずっと前に出た名詞が、あとから出てくる代名詞に効く。
文末の否定が、文全体の意味を反転させる。
ある形容詞が、離れた名詞の印象を変える。
一つの単語が、別の単語の意味を曲げる。
文章は線でありながら、同時に網でもある。
Transformerは、その網のほうをかなり直接的に扱おうとしたモデルなのかもしれません。
この見方をすると、Attentionという名前も少しわかる気がします。
意味とは、どこを見るかで変わる。
そしてモデルは、その「どこを見るか」を学習している。
まとめ
Attention Is All You Needは、Transformerを提案した論文です。
この論文では、RNNやCNNを使わず、Attentionを中心にしたモデルで機械翻訳に高い性能を出せることが示されました。
重要なポイントは、だいたい次のあたりです。
- Self-Attentionによって、トークン同士の関係を直接見る
- Query / Key / Value によって、検索のように情報を取り出す
- Scaled Dot-Product Attentionで、相性を計算してValueを混ぜる
- Multi-Head Attentionで、複数の観点から文を見る
- Positional Encodingで、順序情報を補う
- Encoder-Decoder構造で、入力文を読み、出力文を生成する
- FFNで各トークンの情報を非線形に変換する
- 残差接続やLayerNormで深いモデルを安定させる
- RNNより並列化しやすく、大規模化に向いていた
今読むと、元のTransformerは現在のLLMとは違う部分も多いです。
でも、
トークン同士の関係をAttentionで結び、文脈を処理する
という基本発想は、今のLLMにも深く残っています。
そして、RoPE、SwiGLU、RMSNorm、FlashAttention、MoEなどの最近の部品も、Transformerの各パーツを改造したものとして見ると、かなり理解しやすくなります。
この論文は、単に古典的な有名論文というより、今のAIが、なぜこういう形をしているのかを知るための入口だと思います。
おわりに
ここで、勉強してきたことを含めてアーキテクチャ図を思い出してみましょう。
![]()
……どうですか?一気に親しみやすくなった、そんな気がしませんか?
Attentionという仕組みは、最初に見ると少し不思議です。
単語からQuery、Key、Valueを作る。
内積を取る。
softmaxする。
Valueを混ぜる。
やっていることは線形代数でよくわからないことをやってるように見えるのですが、見方を知ると、
文章の中で、各単語がどこを見るべきかを学習する
仕組みであることがわかります。
文章を前から順番に読むだけではなく、
言葉と言葉の間に張られた見えない糸を見る。
Transformerは、その糸の張り方を学習するモデルなのかもしれません。
タイトルは Attention Is All You Need。
本当にAttentionだけで全部だったのか、というと、実際にはFFNもLayerNormも残差接続も位置エンコーディングもあります。
なので、ちょっと盛っています。
でも、少なくともこの論文以降、「どこを見るか」は、自然言語処理の中心的な問いになりました。
そして最近のLLMは、その「どこを見るか」を、もっと速く、もっと長く、もっと深く、もっと安定して行うために、さまざまな部品を足したり置き換えたりしてきたものとして見ることができます。
次は、この骨格の上に乗っている最近のアーキテクチャをもう少し詳しく見ていきたいです。DeepSeekとかQWENあたり。
参考・引用
-
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin, Attention Is All You Need
Transformerを提案した元論文です。Self-Attention、Multi-Head Attention、Positional Encoding、Encoder-Decoder構造など、この記事の中心的な内容はこの論文をもとにしています。 -
Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, Yunfeng Liu, RoFormer: Enhanced Transformer with Rotary Position Embedding
RoPE、Rotary Position Embeddingを提案した論文です。位置情報をQueryとKeyの回転としてAttentionに組み込む、という考え方の参考にしています。 -
Noam Shazeer, GLU Variants Improve Transformer
TransformerのFFNにおけるGLU系の活性化、特にSwiGLUなどの有効性を示した論文です。最近のLLMでよく使われるGated MLPの背景として参照しています。 -
Biao Zhang, Rico Sennrich, Root Mean Square Layer Normalization
RMSNormを提案した論文です。LayerNormとの違いや、最近のLLMで使われる正規化の背景を理解するために参照しています。 -
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré, FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Attentionの意味を変えずに、GPU上で高速かつ省メモリに計算するFlashAttentionの論文です。LLMが数学だけではなくシステム最適化でもあることを理解するために重要です。 -
Noam Shazeer et al., Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Mixture of Expertsの代表的な初期論文です。大量のExpertを用意し、入力ごとに一部だけを使うという発想の背景として参照しています。 -
Mor Geva, Roei Schuster, Jonathan Berant, Omer Levy, Transformer Feed-Forward Layers Are Key-Value Memories
TransformerのFFN層が、入力パターンに応じて値を取り出すkey-value memoryのように働く、という見方を示した論文です。FFN/MLPに知識が蓄えられているという豆知識の参考にしています。 -
Kevin Meng, David Bau, Alex Andonian, Yonatan Belinkov, Locating and Editing Factual Associations in GPT
ROMEの論文です。GPT系モデルにおける事実知識の所在を解析し、中間層のMLPがfactual associationに強く関わることを示しています。 -
DeepSeek-AI, DeepSeek-V3 Technical Report
DeepSeek-V3の技術報告です。MoE構造によって、総パラメータ数を大きくしつつ推論時の計算量を抑える例として参照しています。 -
DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1の論文です。MoE構造でも高い推論能力を持つモデルが成立している例として参照しています。 -
Jay Alammar, The Illustrated Transformer
Transformerの構造を図で理解するための定番記事です。初学者向けにかなりわかりやすく、AttentionやEncoder-Decoderの流れを視覚的に把握する助けになります。 -
Lilian Weng, Attention? Attention!
Attention機構の流れを整理した記事です。Transformer以前のAttentionからSelf-Attentionまでを見渡すときの参考になります。


